基于RK3576开发板的AI算法开发流程
1. 概述
AI算法开辟流程由以下贱程构成:

2. 需供剖析
算法的功用经常能够用一个短词归纳综合,如人脸辨认、司机行动检测、阛阓主顾行动剖析等零碎,可是却需求依托多个子算法的有序运做才干告竣。其缘由正在于子算法的神经收集构造各有分歧,那些构造的差别化劣化了各个子算法正在其功用上的完成结果。
| 模子分类称号 | 功用 |
| 目的检测模子 | 检测图象中能否存正在目的物体,并给出其正在图象中的详细坐标,可同时供给分类功用 |
| 要害面定位模子 | 检测图象中的特定目的,并标出要害面位,罕见骨骼面位、脸部器民面位等 |
| 类似度比对模子 | 比拟两个分歧的集体的类似度,罕见人脸、猪脸辨认,商品辨认 |
| 联系模子 | 检测图象中存正在的物体,按表面或其他规范联系出物体地点的没有法则像素地区,可同时带分类功用 |
| OCR模子 |
以下我们列出构成例子:
例子a: 人脸辨认算法 = 人脸检测(检测模子)+ 改正人脸姿势模子(要害面定位模子)+ 人脸比对模子(类似度比对模子)
例子b: 司机行动检测算法 = 人脸辨认算法(详细构成如上例)+ 吸烟玩脚机等风险举措辨认(检测模子) + 疲惫驾驶检测(要害面定位模子)+ 车讲线偏偏移检测(检测模子)
例子c: 阛阓剖析 = 人脸辨认算法(详细构成如尾例)+ 人体跟踪算法(检测模子 + 类似度比对模子)
只要正在肯定了详细需供所需求的步调后,我们才干对症下药的收集数据,劣化模子,练习出符合我们需供的模子。
3. 预备数据
即便预备数据正在年夜少数人看去是烦琐反复的任务,那时期仍有很多细节需求留意的。
数据样本需求杰出的多样性。样本多样性是包管算法泛化才能的根底,比方念要辨认农产物的功用中,假设我们只是汇集白苹果的数据,那末练习出去的收集便很易将绿色的苹果精确辨认出。同时借需求参加足够的背样本,比方我们只是纯真天把农产物的图片数据喂给神经收集,那末我们便很易希冀练习出去的神经收集能够无效辨别实苹果借有塑料苹果。为了加强算法的牢靠性,我们便需求充沛的思索到实践使用场景中会呈现甚么非凡状况,并将该种状况的数据增加进我们的练习数据外面。
数据样本能否可被紧缩。单个样本数据的巨细常常决议了收集模子的运转效力,正在包管结果的状况下,该当尽可能紧缩图片的巨细去进步运转效力,如112x112的图片,正在相反情况下的处置速率将比224x224图片的快4倍摆布。可是有些场景倒是需求完好的图片去包管图片疑息没有会丧失,如山水检测普通需求很下的查齐率,过分的紧缩城市招致查齐率降落招致算法结果欠安。
数据需求适宜准确的标注取预处置。数据标注正在必然水平上决议了练习结果能到达的下度,过量的毛病标志将带去一个有效的练习后果。而数据的预处置,是指先对数据做出必然的操纵,使其更轻易被机械读懂,比方农产物正在绘里中的地位,假如是以像素面为单元,如农产物的中间面正在左起第200个像素面,这类处置体例固然曲不雅精确,可是会由于分歧像素面之间的差异过年夜,招致练习坚苦,那个时分便需求将间隔回一化,如中间面正在图中左起40%宽的地位上。而音频的预处置更加多样,分歧的分词体例、傅里叶变更城市影响练习后果。
数据的预备纷歧定得正在一开端便做到毫无脱漏。模子练习完成后,假如有必然的结果但借存正在局部缺点,便可以思索增加或劣化练习样本数据,对已有模子停止复练习批改。即便是前期的劣化,增加适宜的照片常常是最无效的结果。以是对数据的考量劣化应当贯串全部流程,不克不及正在只是正在扫尾阶段才存眷数据样本的成绩。
4. 拔取模子
凡是来说,关于统一个功用,存正在着分歧的模子,它们正在粗度、计较速度上各有优点。模子去发明次要来历于教术研讨、公司之间的地下竞赛等,以是正在研收进程中,便需从业职员继续天存眷有闭ai新模子的文章;同时对旧模子的积聚剖析也是非常主要的,那里我们正在 下表 中列出今朝正在各个功用上较劣的模子构造以供参考。
| 模子范例 | 模子称号 | 结果 | 速度 |
| 检测模子 | yolov5 | 粗度下 | 中等 |
| 检测模子 | ssd | 粗度中等,对小物体的辨认普通 | 疾速 |
| 要害面定位模子 | mtcnn | 粗度普通,要害面较少 | 快 |
| 要害面的定位模子 | openpose | 粗度下,要害面多 | 中等 |
| 类似度比对模子 | resnet18 | 粗度下 | 疾速 |
| 类似度比对模子 | resnet50 | 粗度下,鲁棒性强,有比拟强的抗搅扰才能 | 中等 |
| 联系模子 | mask-rcnn | 粗度中,联系出绘里中的没有法则物体 | 缓 |
5. 练习模子
关于有AI开辟经历的研收职员,能够用本人熟习的罕见框架练习便可,如tensorflow、pytorch、caffe等支流框架,我们的开辟套件能够将其转为EASY EAI Orin-nano的公用模子。
6. 模子转换
研收tensorflow、pytorch、caffe等自立的模子后,需先将模子转换为rknn模子。同时普通需求对模子停止量化取预编译,以到达运转效力的晋升。
6.1 模子转换情况拆建
6.1.1 概述
模子转换情况拆建流程以下所示:

6.1.2 下载模子转换东西
为了包管模子转换东西顺遂运转,请下载网盘里“06.AI算法开辟/01.rknn-toolkit2模子转换东西/rknn-toolkit2-v2.3.0/docker/rknn-toolkit2-v2.3.0-cp38-docker.tar.gz”。
网盘下载链接:https://pan.百度.com/s/1J86chdq1klKFnpCO1RCcEA?pwd=1234提与码:1234
6.1.3 把东西移到ubuntu20.04
把下载完成的docker镜像移到我司的实拟机ubuntu20.04的rknn-toolkit目次,以下图所示:
6.1.4 运转模子转换东西情况
6.1.4.1 翻开末端
正在该目次翻开末端
6.1.4.2 减载docker镜像
履行以下指令减载模子转换东西docker镜像:
docker load --input rknn-toolkit2-v2.3.0-cp38-docker.tar.gz
6.1.4.3 进进镜像bash情况
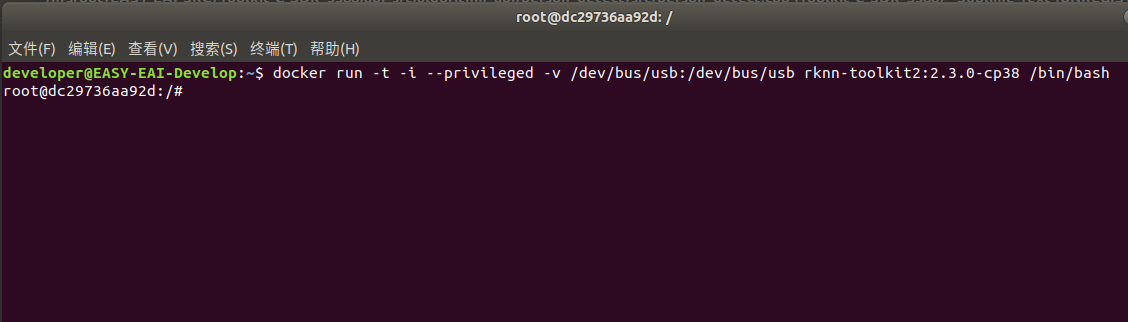
履行以下指令进进镜像bash情况:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb rknn-toolkit2:2.3.0-cp38 /bin/bash
景象以下图所示:
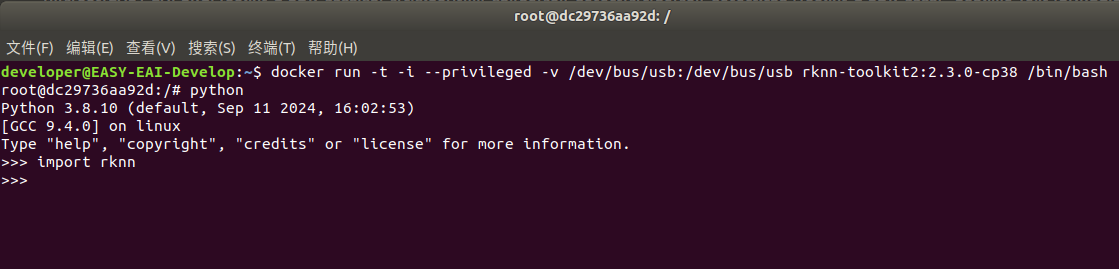
输出“python”减载python相干库,测验考试减载rknn库,以下图情况测试胜利:
至此,模子转换东西情况拆建完成。
6.2 模子转换教程示例
6.2.1 模子转换为RKNN
EASY EAI Monster撑持.rknn后缀的模子的评价及运转,关于罕见的tensorflow、tensroflow lite、caffe、darknet、onnx战Pytorch模子皆能够经过我们供给的 toolkit 东西将其转换至 rknn 模子,而关于其他框架练习出去的模子,也能够先将其转至 onnx 模子再转换为 rknn 模子。
模子转换操纵流程进下图所示:

6.2.2 模子转换Demo下载
下载百度网链接:https://pan.百度.com/s/1l5vcbS-w4dGetSdKQdhAuA?pwd=1234 提与码:1234。把yolov5_model_convert.tar.bz2战quant_dataset.zip解压到实拟机,以下图所示:
6.2.3 进进模子转换东西docker情况
履行以下指令把任务地区映照进docker镜像,此中/home/developer/rknn-toolkit2/model_convert为任务地区,/test为映照到docker镜像,/dev/bus/usb:/dev/bus/usb为映照usb到docker镜像:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/developer/rknn-toolkit2/model_convert:/test rknn-toolkit2:2.3.0-cp38 /bin/bash
履行胜利以下图所示:
6.2.4 模子转换操纵阐明
6.2.4.1 模子转换Demo目次构造
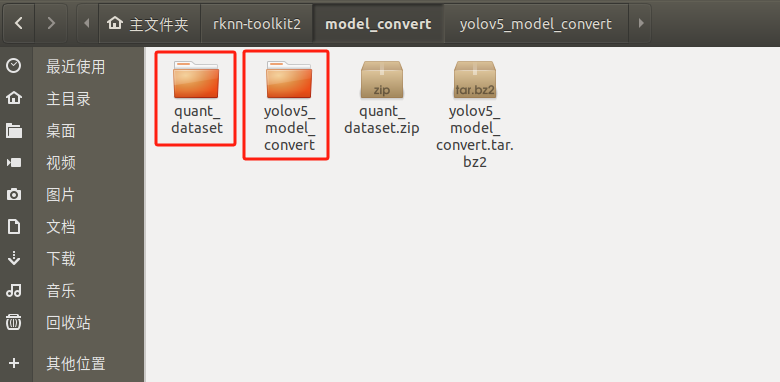
模子转换测试Demo由yolov5_model_convert战quant_dataset构成。yolov5_model_convert寄存硬件剧本,quant_dataset寄存量化模子所需的数据。以下图所示:
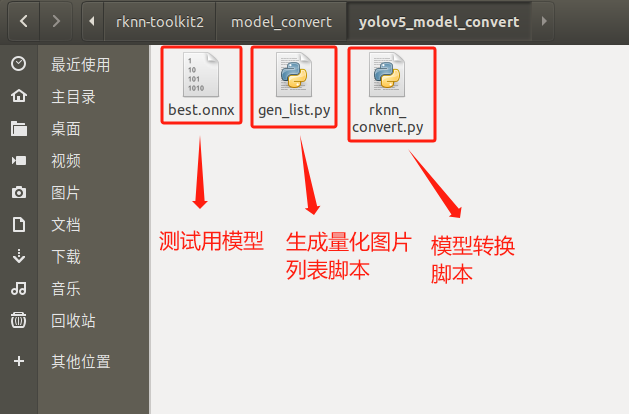
yolov5_model_convert文件夹寄存以下内容,以下图所示:
6.2.4.2 死成量化图片列表
正在docker情况切换到模子转换任务目次:
cd /test/yolov5_model_convert
以下图所示:
履行gen_list.py死成量化图片列表:
python gen_list.py
号令止景象以下图所示:
死成“量化图片列表”以下文件夹所示:
6.2.4.3 onnx模子转换为rknn模子
rknn_convert.py剧本默许停止int8量化操纵,剧本代码浑单以下所示:
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
ONNX_MODEL = 'best.onnx'
RKNN_MODEL = './yolov5_mask_rk3576.rknn'
DATASET = './pic_path.txt'
QUANTIZE_ON = True
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
if not os.path.exists(ONNX_MODEL):
print('model not exist')
exit(-1)
# pre-process config
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
target_platform = 'rk3576')
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load yolov5 failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
if ret != 0:
print('Build yolov5 failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export yolov5rknn failed!')
exit(ret)
print('done')
把onnx模子best.onnx放到yolov5_model_convert目次,并履行rknn_convert.py剧本停止模子转换:
python rknn_convert.py
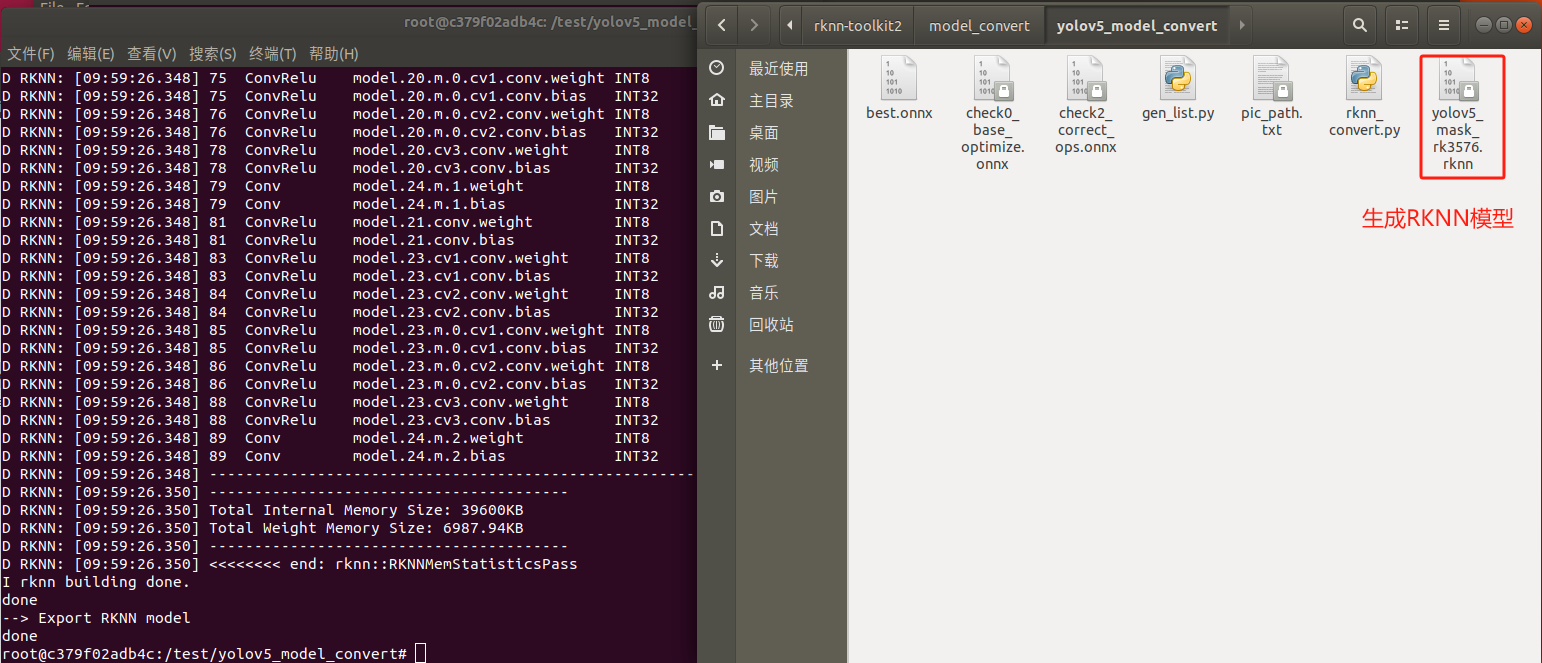
死成模子以下图所示,此模子能够正在rknn情况战EASY EAI Orin-nano情况运转:
6.3 模子转换API阐明
6.3.1 API具体阐明
6.3.1.1 RKNN初初化及开释
正在运用RKNN-Toolkit2的一切API接心时,皆需求先挪用RKNN()办法初初化RKNN工具,没有再运用该工具时经过挪用该工具的release()办法停止开释。
初初化RKNN工具时,能够设置verbose战verbose_file参数,以挨印具体的日记疑息。此中verbose参数指定能否要挨印具体日记疑息;假如设置了verbose_file参数,且verbose参数值为True,日记疑息借将写到该参数指定的文件中。
举比方下:
# 挨印具体的日记疑息 rknn = RKNN(verbose=True) … rknn.release()
6.3.1.2 模子设置装备摆设
正在构建RKNN模子之前,需求先对模子停止通讲均值、量化图片RGB2BGR转换、量化范例等的设置装备摆设,那些操纵能够经过config接心停止设置装备摆设。
| API | config |
| 描绘 | 设置模子转换参数。 |
| 参数 |
mean_values:输出的均值。参数格局是一个列表,列表中包括一个或多个均值子列表,多输出模子对应多个子列表,每一个子列表的少度取该输出的通讲数分歧,比方[[128,128,128]],暗示一个输出的三个通讲的值加来128。 默许值为None,暗示一切的mean值为0。 |
|
std_values:输出的回一化值。参数格局是一个列表,列表中包括一个或多个回一化值子列表,多输出模子对应多个子列表,每一个子列表的少度取该输出的通讲数分歧,比方[[128,128,128]],暗示设置一个输出的三个通讲的值加来均值后再除以128。 默许值为None,暗示一切的std值为1。 |
|
|
quant_img_RGB2BGR:暗示正在减载量化图象时能否需求先做RGB2BGR的操纵。假如有多个输出,则用列表包括起去,如[True, True, False]。默许值为False。 该设置装备摆设普通用正在Caffe的模子上,Caffe模子练习时年夜多会先对数据散图象停止RGB2BGR转换,此时需将该设置装备摆设设为True。 别的,该设置装备摆设只对量化图象格局为jpg/png/bmp无效,npy格局读与时会疏忽该设置装备摆设,因而当模子输出为BGR时,npy也需求为BGR格局。 该设置装备摆设仅用于正在量化阶段(build接心)读与量化图象或量化粗度剖析(accuracy_analysis 接心),其实不会保管正在终究的RKNN模子中,因而假如模子的输出为BGR,则正在挪用toolkit2的inference或C-API的run函数之前,需求包管传进的图象数据也为BGR格局。 |
|
|
quantized_dtype:量化范例,今朝撑持的量化范例有w8a8、w4a16、w8a16、w4a8、w16a16i战w16a16i_dfp。默许值为w8a8。 - w8a8:权重为8bit非对称量化粗度,激活值为8bit非对称量化粗度。(RK2118没有撑持) - w4a16:权重为4bit非对称量化粗度,激活值为16bit浮面粗度。(仅RK3576撑持) - w8a16:权重为8bit非对称量化粗度,激活值为16bit浮面粗度。(仅RK3562撑持) - w4a8:权重为4bit非对称量化粗度,激活值为8bit非对称量化粗度。(久没有撑持) - w16a16i:权重为16bit非对称量化粗度,激活值为16bit非对称量化粗度。(仅RV1103/RV1106撑持) - w16a16i_dfp:权重为16bit静态定面量化粗度,激活值为16bit静态定面量化粗度。(仅RV1103/RV1106撑持) |
|
|
quantized_algorithm:计较每层的量化参数时采取的量化算法,今朝撑持的量化算法有:normal,mmse及kl_divergence。默许值为normal。 normal量化算法的特性是速率较快,引荐量化数据量普通为20-100张摆布,更多的数据量下粗度一定会有进一步晋升。 mmse量化算法因为采取暴力迭代的体例,速率较缓,但凡是会比normal具有更下的粗度,引荐量化数据量普通为20-50张摆布,用户也能够依据量化工夫是非对量化数据量停止恰当删加。 kl_divergence量化算法所用工夫会比normal多一些,但比mmse会少良多,正在某些场景下(feature散布没有平均时)能够失掉较好的改良结果,引荐量化数据量普通为20-100张摆布。 |
|
|
quantized_method:今朝撑持layer或许channel。默许值为channel。 - layer:每层的weight只要一套量化参数; - channel:每层的weight的每一个通讲皆有一套量化参数,凡是状况下channel会比layer粗度更下。 |
|
|
float_dtype:用于指定非量化状况下的浮面的数据范例,今朝撑持的数据范例有float16。 默许值为float16。 |
|
| optimization_level:模子劣化品级。默许值为3。经过修正模子劣化品级,能够闭失落局部或全数模子转换进程中运用到的劣化法则。该参数的默许值为3,翻开一切劣化选项。值为2或1时封闭一局部能够会对局部模子粗度发生影响的劣化选项,值为0时封闭一切劣化选项。 | |
| target_platform:指定RKNN模子是基于哪一个目的芯片仄台死成的。今朝撑持“rv1103”、“rv1103b”、“rv1106”、“rv1106b”、“rk2118”、“rk3562”、“rk3566、“rk3568”、“rk3576”战“rk3588”。该参数对巨细写没有敏感。默许值为None。 | |
| custom_string:增加自界说字符串疑息到RKNN模子,能够正在runtime时经过query查询到该疑息,便利摆设时依据分歧的RKNN模子做非凡的处置。默许值为None。 | |
| remove_weight:来除conv等权重以死成一个RKNN的从模子,该从模子能够取带完好权重的RKNN模子同享权重以增加内存耗费。默许值为False。 | |
| compress_weight:紧缩模子权重,能够加小RKNN模子的巨细。默许值为False。 | |
| single_core_mode:能否仅死成单核模子,能够加小RKNN模子的巨细战内存耗费。默许值为False。今朝仅对RK3588 / RK3576失效。默许值为False。 | |
| model_pruning:对模子停止无益剪枝。关于权重稀少的模子,能够加小转换后RKNN模子的巨细战计较量。默许值为False。 | |
| op_target:用于指定OP的详细履行目的(如NPU/CPU/GPU等),格局为{'op0_output_name':'cpu', 'op1_output_name':'npu', ...}。默许值为None。此中,'op0_output_name'战'op1_output_name'为对应OP的输入tensor名,能够经过粗度剖析(accuracy_analysis)功用的前往后果中获得。'cpu'战'npu'则暗示该tensor对应的OP的履行目的是CPU或NPU,今朝可选的选项有:'cpu' / 'npu' / 'gpu' / 'auto',此中,'auto'是主动挑选履行目的。 | |
|
dynamic_input:用于依据用户指定的多组输出shape,去模仿静态输出的功用。格局为[[input0_shapeA, input1_shapeA, ...], [input0_shapeB, input1_shapeB, ...], ...]。 默许值为None,尝试性功用。 假定本初模子只要一个输出,shape为[1,3,224,224],或许本初模子的输出shape自身便是静态的,如shape为[1,3,height,width]或[1,3,-1,-1],但摆设的时分,需求该模子撑持3种分歧的 输出shape,如[1,3,224,224], [1,3,192,192]战[1,3,160,160],此时能够设置dynamic_input=[[[1,3,224,224]], [[1,3,192,192]], [[1,3,160,160]]],转换成RKNN模子落后止推理时,需传进对应shape的输出数据。 注: 需求本初模子自身撑持静态输出才可开启此功用,不然会报错。 假如本初模子输出shape自身便是静态的,则只要静态的轴能够设置分歧的值。 |
|
|
quantize_weight:正在build接心的do_quantization为False状况下, 经过对一些权重停止量化以加小rknn模子的巨细。 默许值为False。 |
|
|
remove_reshape:删除模子的输出战输入中能够存正在的Reshape的OP,以进步模子运转时功能(由于今朝良多仄台的Reshape是跑正在cpu上,绝对较缓)。 默许为 False。 注:开启后能够会修正模子的输出或输入节面的shape,需求寄望察看转换进程中的warning挨印,并正在摆设时也需求思索输出战输入shape转变的影响。 |
|
| sparse_infer:正在曾经稀少化过的模子长进止稀少化推理,以进步推感性能。 今朝仅对RK3576失效。默许为 False。 | |
|
enable_flash_attention:能否启用Flash Attention。默许为 False。 注:FlashAttention是基于 https://arxiv.org/abs/2307.08691 完成, 经过下速缓存内轮回完成减速和增加宽带运用,可是会招致模子删年夜,请依据详细场景战模子挑选能否开启运用。更多概况请检查“RKNN Compiler Support Operator List”的exSDPAttention阐明。 |
|
| 前往值 | 无。 |
举比方下:
# model config
rknn.config(mean_values=[[103.94, 116.78, 123.68]],
std_values=[[58.82, 58.82, 58.82]],
quant_img_RGB2BGR=True,
target_platform='rk3566')
6.3.1.3 模子减载
RKNN-Toolkit2今朝撑持Caffe、TensorFlow、TensorFlow Lite、ONNX、DarkNet、PyTorch等模子的减载转换,那些模子正在减载时需挪用对应的接心,以下为那些接心的具体阐明。
(1)Caffe模子减载接心
| API | load_caffe |
| 描绘 | 减载Caffe模子。(ARM64版本久没有撑持该接心) |
| 参数 | model:Caffe模子文件(.prototxt后缀文件)途径。 |
| blobs:Caffe模子的两进造数据文件(.caffemodel后缀文件)途径。 | |
|
input_name:Caffe模子存正在多输出时,能够经过该参数指定输出层名的挨次,形如['input1','input2','input3'],留意名字需求取模子输出名分歧;默许值为None,暗示按Caffe 模子文件(.prototxt后缀文件)主动给定。 |
|
| 前往值 | 0:导进胜利。 |
| -1:导进掉败。 |
举比方下:
# 从以后途径减载mobilenet_v2模子
ret = rknn.load_caffe(model='./mobilenet_v2.prototxt',
blobs='./mobilenet_v2.caffemodel')
(2)TensorFlow模子减载接心
| API | load_tensorflow |
| 描绘 | 减载TensorFlow模子。(ARM64版本久没有撑持该接心) |
| 参数 | tf_pb:TensorFlow模子文件(.pb后缀)途径。 |
| inputs:模子的输出节面(tensor名),撑持多个输出节面。一切输出节面名放正在一个列表中。 | |
| input_size_list:每一个输出节面对应的shape,一切输出shape放正在一个列表中。如示例中的ssd_mobilenet_v1模子,其输出节面对应的输出shape是[[1, 300, 300, 3]]。 | |
| outputs:模子的输入节面(tensor名),撑持多个输入节面。一切输入节面名放正在一个列表中。 | |
| input_is_nchw:模子的输出的layout能否曾经是NCHW。默许值为False,暗示默许输出layout为NHWC。 | |
| 前往值 | 0:导进胜利。 |
| -1:导进掉败。 |
举比方下:
# 从以后目次减载ssd_mobilenet_v1_coco_2017_11_17模子
ret = rknn.load_tensorflow(tf_pb='./ssd_mobilenet_v1_coco_2017_11_17.pb',
inputs=['Preprocessor/sub'],
outputs=['concat', 'concat_1'],
input_size_list=[[300, 300, 3]])
(3)TensorFlow Lite模子减载接心
| API | load_tflite |
| 描绘 | 减载TensorFlow Lite模子。(ARM64版本久没有撑持该接心) |
| 参数 | model:TensorFlow Lite模子文件(.tflite后缀)途径。 |
| input_is_nchw:模子的输出的layout能否曾经是NCHW。默许值为False,即默许输出layout为NHWC。 | |
| 前往值 | 0:导进胜利。 |
| -1:导进掉败。 |
举比方下:
# 从以后目次减载mobilenet_v1模子 ret = rknn.load_tflite(model='./mobilenet_v1.tflite')
(4)ONNX模子减载
| API | load_onnx |
| 描绘 | 减载ONNX模子。 |
| 参数 | model:ONNX模子文件(.onnx后缀)途径。 |
| inputs:模子输出节面(tensor名),撑持多个输出节面,一切输出节面名放正在一个列表中。默许值为None,暗示从模子里获得。 | |
| input_size_list:每一个输出节面对应的shape,一切输出shape放正在一个列表中。如inputs有设置,则input_size_list也需求被设置。默许值为None。 | |
| input_initial_val:设置模子输出的初初值,格局为ndarray的列表。默许值为None。 次要用于将某些输出固化为常量,关于没有需求固化为常量的输出能够设为None,如[None,np.array([1])]。 | |
| outputs:模子的输入节面(tensor名),撑持多个输入节面,一切输入节面名放正在一个列表中。默许值为None,暗示从模子里获得。 | |
| 前往值 | 0:导进胜利。 |
| -1:导进掉败。 |
举比方下:
# 从以后目次减载arcface模子 ret = rknn.load_onnx(model='./arcface.onnx')
(5)DarkNet模子减载接心
| API | load_darknet |
| 描绘 | 减载DarkNet模子。(ARM64版本久没有撑持该接心) |
| 参数 | model:DarkNet模子文件(.cfg后缀)途径。 |
| weight:权重文件(.weights后缀)途径。 | |
| 前往值 | 0:导进胜利。 |
| -1:导进掉败。 |
举比方下:
# 从以后目次减载yolov3-tiny模子
ret = rknn.load_darknet(model='./yolov3-tiny.cfg',
weight='./yolov3.weights')
(6)PyTorch模子减载接心
| API | load_pytorch |
| 描绘 | 减载PyTorch模子。 撑持量化感知练习(QAT)模子,但需求将torch版本更新至1.9.0以上。 |
| 参数 | model:PyTorch模子文件(.pt后缀)途径,并且需求是torchscript格局的模子。 |
| input_size_list:每一个输出节面对应的shape,一切输出shape放正在一个列表中。 | |
| 前往值 | 0:导进胜利。 |
| -1:导进掉败。 |
举比方下:
# 从以后目次减载resnet18模子
ret = rknn.load_pytorch(model='./resnet18.pt',
input_size_list=[[1,3,224,224]])
6.3.1.4 构建RKNN模子
| API | build |
| 描绘 | 构建RKNN模子。 |
| 参数 | do_quantization:能否对模子停止量化。默许值为True。 |
|
dataset:用于量化校订的数据散。今朝撑持文本文件格局,用户能够把用于校订的图片 (jpg或png格局)或npy文件途径放到一个.txt文件中。文本文件里每止一条途径疑息。 如: a.jpg b.jpg 或 a.npy b.npy 若有多个输出,则每一个输出对应的文件用空格离隔,如: a.jpg a2.jpg b.jpg b2.jpg 或 a.npy a2.npy b.npy b2.npy 注:量化图片倡议挑选取猜测场景较符合的图片。 |
|
|
rknn_batch_size:模子的输出Batch参数调剂。默许值为None,暗示没有停止调剂。 假如年夜于1,则能够正在一次推理中同时推理多帧输出图象或输出数据,如MobileNet模子的本初input维度为[1, 224, 224, 3],output维度为[1, 1001],当rknn_batch_size设为4时,input的维度变成[4, 224, 224, 3],output维度变成[4, 1001]。 注: rknn_batch_size只要正在NPU多核的仄台上能够进步功能(晋升中心应用率),因而rknn_batch_size的值倡议取中心数婚配。 rknn_batch_size修正后,模子的input/output的shape城市被修正,运用inference推理模子时需求设置响应的input的巨细,后处置时,也需求对前往的outputs停止处置。 |
|
| 前往值 | 0:构建胜利。 |
| -1:构建掉败。 |
举比方下:
# 构建RKNN模子,而且做量化 ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
6.3.1.5 导出RKNN模子
经过本东西构建的RKNN模子经过该接心能够导出存储为RKNN模子文件,用于模子摆设。
| API | export_rknn |
| 描绘 | 将RKNN模子保管到指定文件中(.rknn后缀)。 |
| 参数 | export_path:导出模子文件的途径。 |
| 前往值 | 0:导出胜利。 |
| -1:导出掉败。 |
举比方下:
# 将构建好的RKNN模子保管到以后途径的mobilenet_v1.rknn文件中 ret = rknn.export_rknn(export_path='./mobilenet_v1.rknn')
6.3.1.6 减载RKNN模子
| API | load_rknn |
| 描绘 |
减载RKNN模子。 减载完RKNN模子后,没有需求再停止模子设置装备摆设、模子减载战构建RKNN模子的步调。而且减载后的模子仅限于衔接NPU硬件停止推理或获得功能数据等,不克不及用于模仿器或粗度剖析等。 |
| 参数 | path:RKNN模子文件途径。 |
| 前往值 | 0:减载胜利。 |
| -1:减载掉败。 |
举比方下:
# 从以后途径减载mobilenet_v1.rknn模子 ret = rknn.load_rknn(path='./mobilenet_v1.rknn')
6.3.1.7 初初化运转时情况
正在模子推理或功能评价之前,必需先初初化运转时情况,明白模子的运转仄台(详细的目的硬件仄台或硬件模仿器)。
| API | init_runtime |
| 描绘 | 初初化运转时情况。 |
| 参数 | target:目的硬件仄台,撑持“rv1103”、“rv1103b”、“rv1106”、“rv1106b”、“rk3562”、“rk3566”、“rk3568”、“rk3576”战“rk3588”。默许值为None,即正在PC运用东西时,模子正在模仿器上运转。 注:target设为None时,需求先挪用build或hybrid_quantization接谈锋可以让模子正在模仿器上运转。 |
| device_id:装备编号,假如PC衔接多台装备时,需求指定该参数,装备编号能够经过“list_devices”接心检查。默许值为None。 | |
| perf_debug:停止功能评价时能否开启debug形式。正在debug形式下,能够获得到每层的运转工夫,不然只能获得模子运转的总工夫。默许值为False。 | |
| eval_mem:能否进进内存评价形式。进进内存评价形式后,能够挪用eval_memory接心获得模子运转时的内存运用状况。默许值为False。 | |
|
async_mode:能否运用同步形式。默许值为False。 挪用推理接心时,触及设置输出图片、模子推理、获得推理后果三个阶段。假如开启了同步形式,设置以后帧的输出将取推理上一帧同时停止,以是除第一帧中,以后的每帧皆能够埋没设置输出的工夫,从而晋升功能。正在同步形式下,每次前往的推理后果皆是上一帧的。(今朝版本该参数久没有撑持) |
|
|
core_mask:设置运转时的NPU中心。撑持的仄台为RK3588 / RK3576,撑持的设置装备摆设以下: RKNN.NPU_CORE_AUTO:暗示主动调剂模子,主动运转正在以后闲暇的NPU核上。 RKNN.NPU_CORE_0:暗示运转正在NPU0中心上。 RKNN.NPU_CORE_1:暗示运转正在NPU1中心上。 RKNN.NPU_CORE_2:暗示运转正在NPU2中心上。 RKNN.NPU_CORE_0_1:暗示同时运转正在NPU0、NPU1中心上。 RKNN.NPU_CORE_0_1_2:暗示同时运转正在NPU0、NPU1、NPU2中心上。 RKNN.NPU_CORE_ALL:暗示依据仄台主动设置装备摆设NPU中心数目。 默许值为RKNN.NPU_CORE_AUTO。 注:RK3576只要2个中心,因而不克不及设置NPU_CORE_2战NPU_CORE_0_1_2。 |
|
| fallback_prior_device:设置当OP超越NPU规格时fallback的劣先级,以后撑持“cpu”或“gpu”,“gpu”只要正在存正在GPU硬件的仄台上无效。默许值是“cpu”。 | |
| 前往值 | 0:初初化运转时情况胜利。 |
| -1:初初化运转时情况掉败。 |
举比方下:
# 初初化运转时情况 ret = rknn.init_runtime(target='rk3566')
6.3.1.8 模子推理
正在停止模子推理前,必需先构建或减载一个RKNN模子。
| API | inference |
| 描绘 |
对以后模子停止推理,并前往推理后果。 假如初初化运转情况时有设置target为Rockchip NPU装备,失掉的是模子正在硬件仄台上的推理后果。假如出有设置target,失掉的则是模子正在模仿器上的推理后果。 |
| 参数 | inputs:待推理的输出列表,格局为ndarray。 |
| data_format:输出数据的layout列表,“nchw”或“nhwc”,只对4维的输出无效。默许值为None,暗示一切输出的layout皆为NHWC。 | |
|
inputs_pass_through:输出的透传列表。默许值为None,暗示一切输出皆没有透传。 非透传形式下,正在将输出传给NPU驱动之前,东西会对输出停止加均值、除圆好等操纵;而透传形式下,没有会做那些操纵,而是间接将输出传给NPU。 该参数的值是一个列表,比方要透传input0,没有透传input1,则该参数的值为[1, 0]。 |
|
| 前往值 | results:推理后果,范例是ndarray list。 |
举比方下:
关于分类模子,如mobilenet_v1,代码以下(完好代码参考example/tflite/mobilent_v1):
# 运用模子对图片停止推理,失掉TOP5后果 outputs = rknn.inference(inputs=[img]) show_outputs(outputs)
输入的TOP5后果以下:
-----TOP 5----- [ 156] score:0.928223 class:"Shih-Tzu" [ 155] score:0.063171 class:"Pekinese, Pekingese, Peke" [ 205] score:0.004299 class:"Lhasa, Lhasa apso" [ 284] score:0.003096 class:"Persian cat" [ 285] score:0.000171 class:"Siamese cat, Siamese"
6.3.1.9 评价模子功能
| API | eval_perf |
| 描绘 |
评价模子功能。 模子必需运转正在取PC衔接的RV1103 / RV1103B / RV1106 / RV1106B / RK3562 / RK3566 /RK3568 / RK3576 / RK3588上。假如挪用“init_runtime”的接心去初初化运转情况时设置 perf_debug为False,则取得的是模子正在硬件上运转的总工夫;假如设置perf_debug为True,除前往总工夫中,借将前往每层的耗时状况。 |
| 参数 | is_print:能否挨印功能疑息,默许值为True。 |
| fix_freq:能否牢固硬件装备的频次,默许值为True。 | |
| 前往值 | perf_result:功能疑息(字符串)。 |
举比方下:
# 对模子功能停止评价 perf_detail = rknn.eval_perf()
6.3.1.10 获得内存运用状况
| API | eval_memory |
| 描绘 |
获得模子正在硬件仄台运转时的内存运用状况。 模子必需运转正在取PC衔接的RV1103 / RV1103B / RV1106 / RV1106B / RK3562 / RK3566 /RK3568 / RK3576 / RK3588上。 |
| 参数 | is_print:能否以标准格局挨印内存运用状况,默许值为True。 |
| 前往值 |
memory_detail:内存运用状况,范例为字典。 内存运用状况依照上面的格局启拆正在字典中: { 'weight_memory': 3698688, 'internal_memory': 1756160, 'other_memory': 484352, 'total_memory': 5939200, } - 'weight_memory' 字段暗示运转时模子权重的内存占用。 - 'internal_memory' 字段暗示运转时模子两头tensor内存占用。 - 'other_memory' 字段暗示运转时其他的内存占用。 - 'total_model_allocation' 暗示运转时的总内存占用,即权重、两头tensor战其他的内存占用之战。 |
举比方下:
# 对模子内存运用状况停止评价 memory_detail = rknn.eval_memory()
如examples/caffe/mobilenet_v2,它正在RK3588上运转时内存占用状况以下:
======================================================
Memory Profile Info Dump
======================================================
NPU model memory detail(bytes):
Weight Memory: 3.53 MiB
Internal Tensor Memory: 1.67 MiB
Other Memory: 473.00 KiB
Total Memory: 5.66 MiB
INFO: When evaluating memory usage, we need consider
the size of model, current model size is: 4.09 MiB
======================================================
6.3.1.11 查询SDK版本
| API | get_sdk_version |
| 描绘 |
获得SDK API战驱动的版本号。 注:运用该接心前必需完成模子减载战初初化运转情况,且该接心只能正在硬件仄台RV1103 / RV1103B / RV1106 / RV1106B / RK3562 / RK3566 / RK3568 / RK3576 / RK3588 上运用。 |
| 参数 | 无。 |
| 前往值 | sdk_version:API战驱动版本疑息,范例为字符串 |
举比方下:
# 获得SDK版本疑息 sdk_version = rknn.get_sdk_version() print(sdk_version)
前往的SDK疑息相似以下:
============================================== RKNN VERSION: API: 1.5.2 (8babfea build@2023-08-25T02:31:12) DRV: rknn_server: 1.5.2 (8babfea build@2023-08-25T10:30:12) DRV: rknnrt: 1.5.3b13 (42cbca6f5@2023-10-27T10:13:21) ==============================================
6.3.1.12 夹杂量化
(1)hybrid_quantization_step1
运用夹杂量化功用时,第一阶段挪用的次要接心是hybrid_quantization_step1,用于死成暂时模子文件
(.model)、数据文件(.data)战量化设置装备摆设文件
(.quantization.cfg)。接心概况以下:
| API | hybrid_quantization_step1 |
| 描绘 | 依据减载的本初模子,死成对应的暂时模子文件、设置装备摆设文件战量化设置装备摆设文件。 |
| 参数 | dataset:睹1.4 构建RKNN模子的dataset阐明。 |
| rknn_batch_size:睹1.4 构建RKNN模子的rknn_batch_size阐明。 | |
| proposal:发生夹杂量化的设置装备摆设倡议值。 默许值为False。 | |
| proposal_dataset_size:proposal运用的dataset的张数。默许值为1。 由于proposal功用比拟耗时,以是默许只运用1张,也便是dataset里的第一张。 | |
|
custom_hybrid:用于依据用户指定的多组输出战输入名,拔取夹杂量化对应子图。格局为[[input0_name, output0_name], [input1_name, output1_name], …]。默许值为None。 注:输出战输入名应依据死成的暂时模子文件(.model)去挑选。 |
|
| 前往值 | 0:胜利。 |
| -1:掉败。 |
举比方下:
# 挪用hybrid_quantization_step1 发生量化设置装备摆设文件 ret = rknn.hybrid_quantization_step1(dataset='./dataset.txt')
(2)hybrid_quantization_step2
用于运用夹杂量化功用时死成RKNN模子,接心概况以下:
| API | hybrid_quantization_step2 |
| 描绘 | 接纳暂时模子文件、设置装备摆设文件、量化设置装备摆设文件战校订数据散做为输出,死成夹杂量化后的RKNN模子。 |
| 参数 | model_input:hybrid_quantization_step1死成的暂时模子文件(.model)途径。 |
| data_input:hybrid_quantization_step1死成的数据文件(.data)途径。 | |
| model_quantization_cfg:hybrid_quantization_step1死成并颠末修正后的模子量化设置装备摆设文件(.quantization.cfg)途径。 | |
| 前往值 | 0:胜利。 |
| -1:掉败。 |
举比方下:
# Call hybrid_quantization_step2 to generate hybrid quantized RKNN model
ret = rknn.hybrid_quantization_step2(
model_input='./ssd_mobilenet_v2.model',
data_input='./ssd_mobilenet_v2.data',
model_quantization_cfg='./ssd_mobilenet_v2.quantization.cfg')
6.3.1.13 量化粗度剖析
该接心的功用是停止浮面、量化推理并发生每层的数据,并停止量化粗度剖析。
| API | accuracy_analysis |
| 描绘 |
推理并发生快照,也便是dump出每层的tensor数据。会dump出包罗fp32战quant两种数据范例的快照,用于计较量化偏差。 注: 该接心只能正在 build 或 hybrid_quantization_step2 以后挪用。 如已指定target,而且本初模子应当为已量化的模子(QAT模子),则会挪用掉败。 该接心运用的量化体例取config中指定的分歧。 |
| 参数 | inputs:图象(jpg / png / bmp / npy等)途径 list。 |
|
output_dir:输入目次,一切快照皆保管正在该目次。默许值为'./snapshot'。 假如出有设置target,正在output_dir下会输入: - simulator目次:保管全部量化模子正在simulator上完好运转时每层的后果(已转成float32); - golden目次:保管全部浮面模子正在simulator上完好跑上去时每层的后果; - error_analysis.txt:记载simulator上量化模子逐层运转时每层的后果取golden浮面模子逐层运转时每层的后果的余弦间隔(entire_error cosine),和量化模子与上一层的浮面后果做为输出时,输入取浮面模子的余弦间隔(single_error cosine),更具体的疑息请检查error_analysis.txt文件。 假如有设置target,则正在output_dir里借会多输入: - runtime目次:保管全部量化模子正在NPU上完好运转时每层的后果(已转成float32)。 - error_analysis.txt:正在上述记载的内容的根底上,借会记载量化模子正在simulator上逐层运转时每层的后果取NPU上逐层运转时每层的后果的余弦间隔(entire_error cosine)等疑息,更具体的疑息请检查error_analysis.txt文件。 |
|
|
target:目的硬件仄台,撑持“rv1103”、“rv1103b”、“rv1106”、“rv1106b”、“rk3562”、“rk3566”、“rk3568”、“rk3576”战“rk3588”,默许为None。 假如设置了target,则会获得NPU运转时每层的后果,并停止粗度的剖析。 |
|
| device_id:装备编号,假如PC衔接多台装备时,需求指定该参数,装备编号能够经过“list_devices”接心检查。默许值为None。 | |
| 前往值 | 0:胜利。 |
| -1:掉败。 |
举比方下:
# Accuracy analysis ret = rknn.accuracy_analysis(inputs=['./dog_224x224.jpg'])
6.3.1.14 获得装备列表
| API | list_devices |
| 描绘 |
列出已衔接的RV1103 / RV1103B / RV1106 / RV1106B / RK3562 / RK3566 / RK3568 /RK3576 / RK3588。 注:今朝装备衔接形式有两种:ADB战NTB。多装备衔接时请确保他们的形式皆是一样的。 |
| 参数 | 无。 |
| 前往值 | 前往adb_devices列表战ntb_devices列表,假如装备为空,则前往空列表。 |
举比方下:
rknn.list_devices()
前往的装备列表疑息以下:
************************* all device(s) with adb mode: VD46C3KM6N *************************
注:运用多装备时,需求包管它们的衔接形式皆是分歧的,不然会惹起抵触,招致装备衔接掉败。
6.3.1.15 导出减稀模子
该接心的功用是将通俗的RKNN模子停止减稀,失掉减稀后的模子。
| API | export_encrypted_rknn_model |
| 描绘 |
依据用户指定的减稀品级对通俗的RKNN模子停止减稀。 注:RV1103/RV1103B/RV1106/RV1106B/RK2118仄台久没有撑持。 |
| 参数 | input_model:待减稀的RKNN模子途径。 |
| output_model:模子减稀后的保管途径。默许值为None,暗示运用{original_model_name}.crypt.rknn做为减稀后的模子名字。 | |
|
crypt_level:减稀品级,有1,2战3三个品级。默许值为1。 品级越下,平安性越下,解稀越耗时;反之,平安性越低,解稀越快。数据范例为整型 |
|
| 前往值 | 0:胜利。 |
| -1:掉败。 |
举比方下:
ret = rknn.export_encrypted_rknn_model('test.rknn')
6.3.1.16 注册自界说算子
该接心的功用是注册一个自界说算子。
| API | reg_custom_op |
| 描绘 | 注册用户供给的自界说算子类。今朝只撑持ONNX模子。 |
| 参数 |
custom_op:用户自界说的算子类。用于用户需求自界说一个没有存正在于ONNX算子标准内的新算子。该算子的op_type引荐以“cst”字符扫尾,而且其算子类的shape_infer战compute 函数需求用户本人完成。 注:custom_op算子类仅用于模子转换并死成带有自界说算子的RKNN模子。 |
| 前往值 | 0:胜利。 |
| -1:掉败。 |
举比方下:
import numpy as np
from rknn.api.custom_op import get_node_attr
class cstSoftmax:
op_type = 'cstSoftmax'
def shape_infer(self, node, in_shapes, in_dtypes):
out_shapes = in_shapes.copy()
out_dtypes = in_dtypes.copy()
return out_shapes, out_dtypes
def compute(self, node, inputs):
x = inputs[0]
axis = get_node_attr(node, 'axis')
x_max = np.max(x, axis=axis, keepdims=True)
tmp = np.exp(x - x_max)
s = np.sum(tmp, axis=axis, keepdims=True)
outputs = [tmp / s]
return outputs
ret = rknn.reg_custom_op(cstSoftmax)
6.3.1.17 死成C++摆设示例
| API | codegen |
| 描绘 | 主动死成C++的摆设示例。 |
| 参数 | output_path:输入文件夹目次,用户可设置装备摆设目次称号。 |
| inputs:挖写模子输出的途径列表,答应没有挖。无效文件格局为jpg/png/npy,以npy文件为输出时,npy数据的维度疑息应取模子输出的维度疑息坚持分歧。 | |
| overwrite:设为True时,会掩盖output_path指定目次下的文件。默许值为alse。 | |
| 前往值 | 0:胜利。 |
| -1:掉败。 |
举比方下:
ret = rknn.codegen(output_path='./rknn_app_demo',
inputs=['./mobilenet_v2/dog_224x224.jpg'],
overwrite=True)
7. 模子摆设
模子转换为rknn模子后,需再参考NPU API阐明文档,编写使用工程。颠末编译后传输至EASY EAI Orin-nano仄台上完成摆设。
7.1 模子摆设示例
7.1.1 模子摆设示例引见
本大节展现yolov5模子的正在EASY EAI Orin-nano的摆设进程,该模子仅颠末复杂练习供示例运用,没有包管模子粗度。
7.1.2 预备任务
7.1.2.1 硬件预备
EASY EAI Orin-nano开辟板,microUSB数据线,该模子仅颠末复杂练习供示例运用,没有包管模子粗度。
7.1.3 源码下载和例程编译
下载yolov5 C Demo示例文件。
百度网盘链接: (https://pan.百度.com/s/1Ah8x8Rzo-iofyZPDHfzo2w?pwd=1234 提与码:1234)。
下载顺序包移至ubuntu情况后,履行以下指令解压:
tar -xvf yolov5_detect_C_demo.tar.bz2
下载解压后以下图所示:
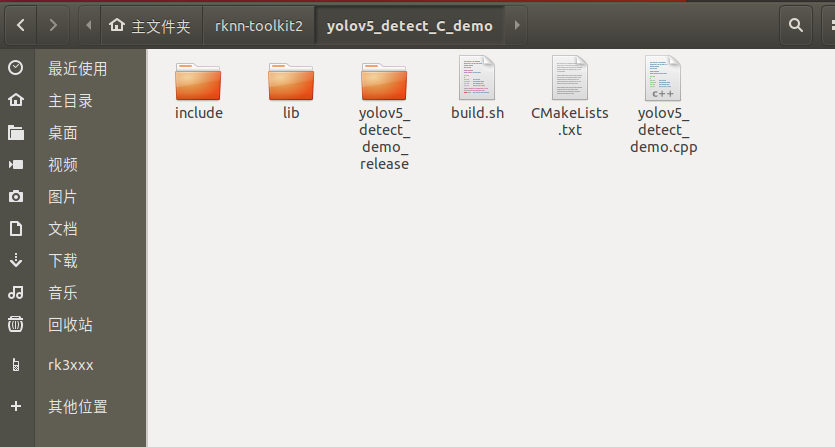
经过adb接心衔接EASY-EAI-Orin-nano,,衔接体例以下图所示:

接上去需求经过adb把源码传输到板卡上,先切换目次然后履行以下指令:
cd ~/rknn-toolkit2 adb push yolov5_detect_C_demo /userdata
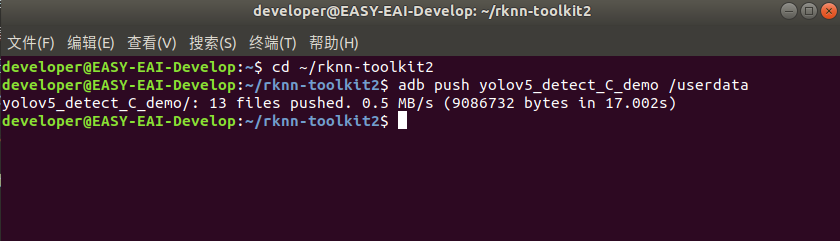
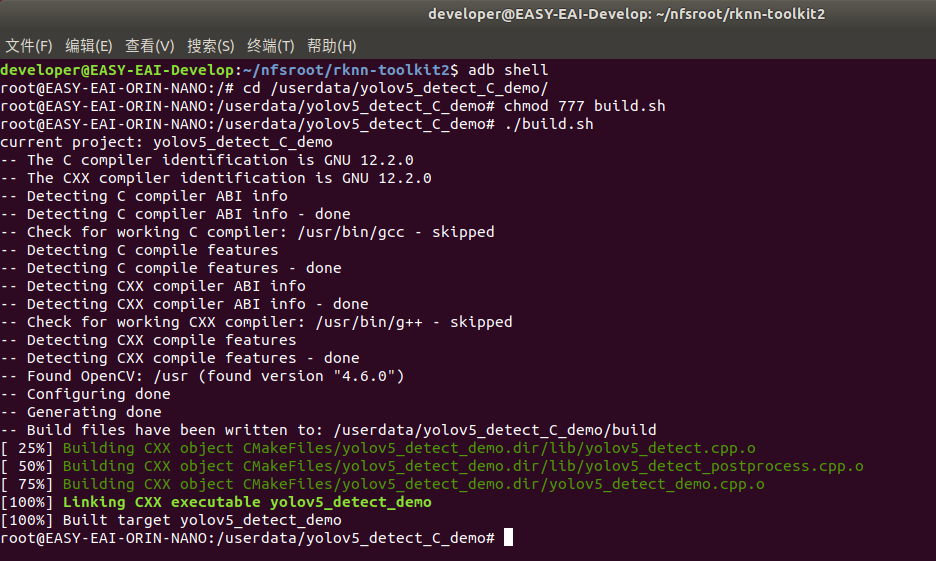
登录到板子切换到例程目次履行编译操纵:
adb shell cd /userdata/yolov5_detect_C_demo chmod 777 build.sh ./build.sh
7.1.4 正在开辟板履行yolov5 demo
编译胜利后切换到可履行顺序目次,以下所示:
cd /userdata/yolov5_detect_C_demo/yolov5_detect_demo_release
运转例程号令以下所示:
chmod 777 yolov5_detect_demo ./yolov5_detect_demo
履行后果以下图所示,算法履行工夫为58ms:

加入板卡情况,与回测试图片:
exit adb pull /userdata/yolov5_detect_C_demo/yolov5_detect_demo_release/result.jpg .
测试后果以下图所示:

至此,yolov5目的检测例程已胜利正在板卡运转。
7.2 模子摆设API阐明
7.2.1 根底数据构造界说
7.2.1.1 rknn_sdk_version
构造体rknn_sdk_version用去暗示RKNN SDK的版本疑息,构造体的界说以下:
| 成员变量 | 数据范例 | 寄义 |
| api_version | char[] | SDK的版本疑息。 |
| drv_version | char[] | SDK所基于的驱动版本疑息。 |
7.2.1.2 rknn_input_output_num
构造体rknn_input_output_num暗示输出输入tensor个数,其构造体成员变量以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| n_input | uint32_t | 输出tensor个数。 |
| n_output | uint32_t | 输入tensor个数。 |
7.2.1.3 rknn_input_range
构造体rknn_input_range暗示一个输出的撑持外形列表疑息。它包括了输出的索引、撑持的外形个数、数据规划格局、称号和外形列表,详细的构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| index | uint32_t | 暗示该外形对应输出的索引地位。 |
| shape_number | uint32_t | 暗示RKNN模子撑持的输出外形个数。 |
| fmt | rknn_tensor_format | 暗示外形对应的数据规划格局。 |
| name | char[] | 暗示输出的称号。 |
| dyn_rang | uint32_t[][] | 暗示输出外形列表,它是包括多个外形数组的两维数组,外形劣先存储。 |
| n_dims | uint32_ | 暗示每一个外形数组的无效维度个数。 |
7.2.1.4 rknn_tensor_attr
构造体rknn_tensor_attr暗示模子的tensor的属性,构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| index | uint32_t | 暗示输出输入tensor的索引地位。 |
| n_dims | uint32_t | Tensor维度个数。 |
| dims | uint32_t[] | Tensor外形。 |
| name | char[] | Tensor称号。 |
| n_elems | uint32_t | Tensor数据元素个数。 |
| size | uint32_t | Tensor数据所占内存巨细。 |
| fmt | rknn_tensor_format | Tensor维度的格局,有以下格局: RKNN_TENSOR_NCHW,RKNN_TENSOR_NHWC, RKNN_TENSOR_NC1HWC2,RKNN_TENSOR_UNDEFINED |
| type | rknn_tensor_type | Tensor数据范例,有以下数据范例:RKNN_TENSOR_FLOAT32, RKNN_TENSOR_FLOAT16,RKNN_TENSOR_INT8, RKNN_TENSOR_UINT8,RKNN_TENSOR_INT16, RKNN_TENSOR_UINT16,RKNN_TENSOR_INT32, RKNN_TENSOR_INT64,RKNN_TENSOR_BOOL |
| qnt_type | rknn_tensor_qnt_type | Tensor量化范例,有以下的量化范例:RKNN_TENSOR_QNT_NONE:已量化;RKNN_TENSOR_QNT_DFP:静态定面量化;RKNN_TENSOR_QNT_AFFINE_ASYMMETRIC:非对称量化。 |
| fl | int8_t | RKNN_TENSOR_QNT_DFP量化范例的参数。 |
| scale | float | RKNN_TENSOR_QNT_AFFINE_ASYMMETRIC量化范例的参数。 |
| w_stride | uint32_t |
实践存储一止图象数据的像素数量,即是一止的无效数据像素数量 + 为硬件疾速逾越到下一止而补齐的一些有效像素数量, 单元是像素。 |
| size_with_stride | uint32_t | 实践存储图象数据所占的存储空间的巨细(包罗了补齐的有效像素的存储空间巨细)。 |
| pass_through | uint8_t | 0暗示已转换的数据,1暗示转换后的数据,转换包罗回一化战量化。 |
| h_stride | uint32_t | 仅用于多batch输出场景,且该值由用户设置。目标是NPU准确天读与每batch数据的肇端地点,它即是本初模子的输出下度+逾越下一列而补齐的有效像素数量。假如设置成0,暗示取本初模子输出下度分歧,单元是像素。 |
7.2.1.5 rknn_perf_detail
构造体rknn_perf_detail暗示模子的功能概况,构造体的界说以下表所示(RV1106/RV1106B/RV1103/RV1103B/RK2118久没有撑持):
| 成员变量 | 数据范例 | 寄义 |
| perf_data | char* | 功能概况包括收集每层运转工夫,可以间接挨印出去检查。 |
| data_len | uint64_t | 寄存功能概况的字符串数组的少度。 |
7.2.1.6 rknn_perf_run
构造体rknn_perf_run暗示模子的整体功能,构造体的界说以下表所示(RV1106/RV1106B/RV1103/RV1103B/RK2118久没有撑持):
| 成员变量 | 数据范例 | 寄义 |
| run_duration | int64_t | 收集整体运转(没有包括设置输出/输入)工夫,单元是微秒。 |
7.2.1.7 rknn_mem_size
构造体rknn_mem_size暗示初初化模子时的内存分派状况,构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| total_weight_size | uint32_t | 模子的权重占用的内存巨细。 |
| total_internal_size | uint32_t | 模子的两头tensor占用的内存巨细。 |
| total_dma_allocated_size | uint64_t | 模子请求的一切dma内存之战。 |
| total_sram_size | uint32_t | 只针对RK3588无效,为NPU预留的零碎SRAM巨细(详细运用体例参考 《RK3588_NPU_SRAM_usage.md》 )。 |
| free_sram_size | uint32_t | 只针对RK3588无效,以后可用的闲暇SRAM巨细(详细运用体例参考《RK3588_NPU_SRAM_usage.md》)。 |
| reserved[12] | uint32_t | 预留。 |
7.2.1.8 rknn_tensor_mem
构造体rknn_tensor_mem暗示tensor的内存疑息。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| virt_addr | void* | 该tensor的实拟地点。 |
| phys_addr | uint64_t | 该tensor的物理地点。 |
| fd | int32_t | 该tensor的文件描绘符。 |
| offset | int32_t | 相较于文件描绘符战实拟地点的偏偏移量。 |
| size | uint32_t | 该tensor占用的内存巨细。 |
| flags | uint32_t | rknn_tensor_mem的标记位,有以下标记:RKNN_TENSOR_MEMORY_FALGS_ALLOC_INSIDE: 表rknn_tensor_mem构造体由运转时创立;RKNN_TENSOR_MEMORY_FLAGS_FROM_FD: 标明rknn_tensor_mem构造体由fd结构;RKNN_TENSOR_MEMORY_FLAGS_FROM_PHYS: 标明rknn_tensor_mem构造体由物理地点结构; 用户不必存眷该标记。 |
| priv_data | void* | 内存的公有数据。 |
7.2.1.9 rknn_input
构造体rknn_input暗示模子的一个数据输出,用去做为参数传进给rknn_inputs_set函数。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| index | uint32_t | 该输出的索引地位。 |
| buf | void* | 输出数据的指针。 |
| size | uint32_t | 输出数据所占内存巨细。 |
| pass_through | uint8_t | 设置为1时会将buf寄存的输出数据间接设置给模子的输出节面,没有做任何预处置。 |
| type | rknn_tensor_type | 输出数据的范例。 |
| fmt | rknn_tensor_format | 输出数据的格局。 |
7.2.1.10 rknn_output
构造体rknn_output暗示模子的一个数据输入,用去做为参数传进给rknn_outputs_get函数,正在函数履行后,构造体工具将会被赋值。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| want_float | uint8_t | 标识能否需求将输入数据转为float范例输入,该字段由用户设置。 |
| is_prealloc | uint8_t | 标识寄存输入数据能否是预分派,该字段由用户设置。 |
| index | uint32_t | 该输入的索引地位,该字段由用户设置。 |
| buf | void* | 输入数据的指针,该字段由接心前往。 |
| size | uint32_t | 输入数据所占内存巨细,该字段由接心前往。 |
7.2.1.11 rknn_init_extend
构造体rknn_init_extend暗示初初化模子时的扩大疑息。构造体的界说以下表所示(RV1106/RV1106B/RV1103/RV1103B/RK2118久没有撑持):
| 成员变量 | 数据范例 | 寄义 |
| ctx | rknn_context | 已初初化的rknn_context工具。 |
| real_model_offset | int32_t | 实正rknn模子正在文件中的偏偏移,只要以文件途径为参数或整拷贝模子内存初初化时才失效。 |
| real_model_size | uint32_t | 实正rknn模子正在文件中的巨细,只要以文件途径为参数或另拷贝模子内存初初化时才失效。 |
| model_buffer_fd | int32_t | 运用RKNN_FLAG_MODEL_BUFFER_ZERO_COPY标记初初化后,NPU分派的模子内存代表的fd。 |
| model_buffer_flags | uint32_t | 运用RKNN_FLAG_MODEL_BUFFER_ZERO_COPY标记初初化后,NPU分派的模子内存代表的内存标记。 |
| reserved | uint8_t[] | 预留数据位。 |
7.2.1.12 rknn_run_extend
构造体rknn_run_extend暗示模子推理时的扩大疑息,今朝久没有撑持运用。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| frame_id | uint64_t | 暗示以后推理的帧序号。 |
| non_block | int32_t | 0暗示梗阻形式,1暗示非梗阻形式,非梗阻即rknn_run挪用间接前往。 |
| timeout_ms | int32_t | 推理超时的下限,单元毫秒。 |
| fence_fd | int32_t | 用于非梗阻履行推理,久没有撑持。 |
7.2.1.13 rknn_output_extend
构造体rknn_output_extend暗示获得输入的扩大疑息,今朝久没有撑持运用。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| frame_id | int32_t | 输入后果的帧序号。 |
7.2.1.14 rknn_custom_string
构造体rknn_custom_string暗示转换RKNN模子时,用户设置的自界说字符串,构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| string | char[] | 用户自界说字符串。 |
7.2.2 根底API阐明
7.2.2.1 rknn_init
rknn_init初初化函数功用为创立rknn_context工具、减载RKNN模子和依据flag战rknn_init_extend构造体履行特定的初初化行动。
| API | rknn_init |
| 功用 | 初初化rknn高低文。 |
| 参数 | rknn_context *context:rknn_context指针。 |
| void *model:RKNN模子的两进造数据或许RKNN模子途径。当参数size年夜于0时,model暗示两进造数据;当参数size即是0时,model暗示RKNN模子途径。 | |
| uint32_t size:当model是两进造数据,暗示模子巨细,当model是途径,则设置为0。 | |
| uint32_t flag:初初化标记,默许初初化行动需求设置为0。 | |
| rknn_init_extend:特定初初化时的扩大疑息。出有运用,传进NULL便可。假如需求同享模子weight内存,则需求传进另个模子rknn_context指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_context ctx; int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
各个初初化标记阐明以下:
RKNN_FLAG_COLLECT_PERF_MASK:用于运转时查询收集各层工夫;RKNN_FLAG_MEM_ALLOC_OUTSIDE:用于暗示模子输出、输入、权重、两头tensor内存全数由用户分派,它次要有两圆里的感化:
一切内存均是用户自止分派,便于对全部零碎内存停止兼顾布置。
用于内存复用,特殊是针对RV1103/RV1106/RV1103B/RV1106B/RK2118这类内存极其重要的状况。假定有模子A、B 两个模子,那两个模子正在设想上串交运止的,那末那两个模子的两头tensor的内存便可以复用。示例代码以下:
rknn_context ctx_a, ctx_b;
rknn_init(&ctx_a, model_path_a, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_a, RKNN_QUERY_MEM_SIZE, &mem_size_a, sizeof(mem_size_a));
rknn_init(&ctx_b, model_path_b, 0, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
rknn_query(ctx_b, RKNN_QUERY_MEM_SIZE, &mem_size_b, sizeof(mem_size_b));
max_internal_size = MAX(mem_size_a.total_internal_size, mem_size_b.total_internal_size);
internal_mem_max = rknn_create_mem(ctx_a, max_internal_size);
internal_mem_a = rknn_create_mem_from_fd(ctx_a, internal_mem_max->fd,
internal_mem_max->virt_addr, mem_size_a.total_internal_size, 0);
rknn_set_internal_mem(ctx_a, internal_mem_a);
internal_mem_b = rknn_create_mem_from_fd(ctx_b, internal_mem_max->fd,
internal_mem_max->virt_addr, mem_size_b.total_internal_size, 0);
rknn_set_internal_mem(ctx_b, internal_mem_b);
RKNN_FLAG_SHARE_WEIGHT_MEM:用于同享另外一个模子的weight权重。次要用于模仿没有定少度模子输出(RKNPU运转时库版本年夜于即是1.5.0后该功用主动态shape功用替换)。比方关于某些语音模子,输出少度没有定,但因为NPU没法撑持没有定少输出,因而需求死成几个分歧分辩率的RKNN模,此中,只要一个RKNN模子的保存完好权重,其他RKNN模子没有带权重。正在初初化没有带权重RKNN模子时,运用该标记能让以后高低文同享完好RKNN模子的权重。假定需求分辩率A、B两个模子,则运用流程以下:
运用RKNN-Toolkit2死成份辨率A的模子。
运用RKNN-Toolkit2死成没有带权重的分辩率B的模子,rknn.config()中,remove_weight要设置成True,次要目标是增加模子B的巨细。
正在板子上,一般初初化模子A。
经过RKNN_FLAG_SHARE_WEIGHT_MEM的flags初初化模子B。
其他依照本来的体例运用。板端参考代码以下:
rknn_context ctx_a, ctx_b; rknn_init(&ctx_a, model_path_a, 0, 0, NULL); rknn_init_extend extend; extend.ctx = ctx_a; rknn_init(&ctx_b, model_path_b, 0, RKNN_FLAG_SHARE_WEIGHT_MEM, &extend);
RKNN_FLAG_COLLECT_MODEL_INFO_ONLY:用于初初化一个空高低文,仅用于挪用rknn_query接心查询模子weight内存总巨细战两头tensor总巨细,没法停止推理;
RKNN_FLAG_INTERNAL_ALLOC_OUTSIDE: 暗示模子两头tensor由用户分派,经常使用于用户自止治理战复用多个模子之间的两头tensor内存;
RKNN_FLAG_EXECUTE_FALLBACK_PRIOR_DEVICE_GPU: 暗示一切NPU没有撑持的层劣先挑选运转正在GPU上,但其实不包管运转正在GPU上,实践运转的后端装备与决于运转时对该算子的撑持状况;
RKNN_FLAG_ENABLE_SRAM: 暗示两头tensor内存尽量分派正在SRAM上;
RKNN_FLAG_SHARE_SRAM: 用于以后高低文测验考试同享另外一个高低文的SRAM内存地点空间,请求以后高低文初初化时必需同时启用RKNN_FLAG_ENABLE_SRAM标记;
RKNN_FLAG_DISABLE_PROC_HIGH_PRIORITY: 暗示以后高低文运用默许历程劣先级。没有设置该标记,历程nice值是-19;
RKNN_FLAG_DISABLE_FLUSH_INPUT_MEM_CACHE: 设置该标记后,runtime外部没有自动革新输出tensor缓存,用户必需确保输出tensor正在挪用 rknn_run 之前已革新缓存。次要用于当输出数据出有CPU拜访时,增加runtime外部刷cache的耗时。
RKNN_FLAG_DISABLE_FLUSH_OUTPUT_MEM_CACHE: 设置该标记后,runtime没有自动肃清输入tensor缓存。此时用户不克不及间接拜访output_mem->virt_addr,那会招致缓存分歧性成绩。 假如用户念运用output_mem->virt_addr,必需运用 rknn_mem_sync (ctx, mem, RKNN_MEMORY_SYNC_FROM_DEVICE)去革新缓存。该标记普通正在NPU的输入数据没有被CPU拜访时运用,比方输入数据由 GPU 或 RGA 拜访以增加革新缓存所需的工夫。
RKNN_FLAG_MODEL_BUFFER_ZERO_COPY:暗示rknn_init接心的传进的模子buffer是rknn_create_mem或许rknn_create_mem2接心分派的内存,runtime外部没有需求拷贝一次模子buffer,增加运转时的内存占用,但需求用户包管高低文烧毁前模子内存无效,而且正在烧毁高低文后开释该内存。初初化高低文时,rknn_init接心的rknn_init_extend参数,其成员real_model_offset、real_model_size、model_buffer_fd战model_buffer_flags依据rknn_create_mem2接心前往的rknn_tensor_mem设置。
RKNN_MEM_FLAG_ALLOC_NO_CONTEXT:正在运用rknn_create_mem2接心分派内存时,设置该标记后,答应ctx参数是0或许NULL。从而用户正在已初初化任何一个高低文之前就可以获得NPU驱动分派的内存,前往的内存构造体需运用rknn_destroy_mem接心开释,开释的接心可以使用恣意一个高低文做为参数。
示例代码以下:
rknn_tensor_mem* model_mem = rknn_create_mem2(ctx, model_size, RKNN_MEM_FLAG_ALLOC_NO_CONTEXT); memcpy(model_mem->virt_addr, model_data, model_size); rknn_init_extend init_ext; memset(&init_ext, 0, sizeof(rknn_init_extend)); init_ext.real_model_offset = 0; init_ext.real_model_size = model_size; init_ext.model_buffer_fd = model_mem->fd; init_ext.model_buffer_flags = model_mem->flags; int ret = rknn_init(&ctx, model_mem->virt_addr, model_size, RKNN_FLAG_MODEL_BUFFER_ZERO_COPY,&init_ext); // do rknn inference... rknn_destroy_mem(ctx, model_mem); rknn_destroy(ctx);
7.2.2.2 rknn_set_core_mask
rknn_set_core_mask函数指定任务的NPU中心,该函数仅撑持RK3576/RK3588仄台,正在单核NPU架构的仄台上设置会前往毛病。
| API | rknn_set_core_mask |
| 功用 | 设置运转的NPU中心。 |
| 参数 | rknn_context context:rknn_context工具。 |
|
rknn_core_mask core_mask:NPU中心的列举范例,今朝有以下体例设置装备摆设: RKNN_NPU_CORE_AUTO:暗示主动调剂模子,主动运转正在以后闲暇的NPU核上; RKNN_NPU_CORE_0:暗示运转正在NPU0核上; RKNN_NPU_CORE_1:暗示运转正在NPU1核上; RKNN_NPU_CORE_2:暗示运转正在NPU2核上; RKNN_NPU_CORE_0_1:暗示同时任务正在NPU0、NPU1核上; RKNN_NPU_CORE_0_1_2:暗示同时任务正在NPU0、NPU1、NPU2核上; RKNN_NPU_CORE_ALL:暗示任务正在一切的NPU中心上 |
|
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_context ctx; rknn_core_mask core_mask = RKNN_NPU_CORE_0; int ret = rknn_set_core_mask(ctx, core_mask);
正在RKNN_NPU_CORE_0_1及RKNN_NPU_CORE_0_1_2形式下,今朝以下OP能取得更好的减速:Conv、DepthwiseConvolution、Add、Concat、Relu、Clip、Relu6、ThresholdedRelu、PRelu、LeakyRelu,其他范例OP将fallback至单核Core0中运转,局部范例OP(如Pool类、ConvTranspose等)将正在后绝更新版本中撑持。
7.2.2.3 rknn_set_batch_core_num
rknn_set_batch_core_num函数指定多batch RKNN模子(RKNN-Toolkit2转换时设置rknn_batch_size年夜于1导出的模子)的NPU中心数目,该函数仅撑持RK3588/RK3576仄台。
| API | rknn_set_batch_core_num |
| 功用 | 设置多batch RKNN模子运转的NPU中心数目。 |
| 参数 | rknn_context context:rknn_context工具。 |
| int core_num:指定运转的中心数目。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_context ctx; int ret = rknn_set_batch_core_num(ctx, 2);
7.2.2.4 rknn_dup_context
rknn_dup_context死成一个指背统一个模子的新context,可用于多线程履行相反模子时的权反复用。RV1106/RV1103/RV1106B/RV1103B/RK2118仄台久没有撑持 。
| API | rknn_dup_context |
| 功用 | 死成统一个模子的两个ctx,复用模子的权重疑息。 |
| 参数 | rknn_context * context_in:rknn_context指针。初初化后的rknn_context工具。 |
| rknn_context * context_out:rknn_context指针。死成新的rknn_context工具。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_context ctx_in; rknn_context ctx_out; int ret = rknn_dup_context(&ctx_in, &ctx_out);
7.2.2.5 rknn_destroy
rknn_destroy函数将开释传进的rknn_context及其相干资本。
| API | rknn_destroy |
| 功用 | 烧毁rknn_context工具及其相干资本。 |
| 参数 | rknn_context context:要烧毁的rknn_context工具。 |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_context ctx; int ret = rknn_destroy(ctx);
7.2.2.6 rknn_query
rknn_query函数可以查询获得到模子输出输入疑息、逐层运转工夫、模子推理的总工夫、SDK版本、内存占用疑息、用户自界说字符串等疑息。
| API | rknn_query |
| 功用 | 查询模子取SDK的相干疑息。 |
| 参数 | rknn_context context:rknn_context工具。 |
| rknn_query_cmd :查询号令。 | |
| void* info:寄存前往后果的构造体变量。 | |
| uint32_t size:info对应的构造体变量的巨细。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
以后SDK撑持的查询号令以下表所示:
| 查询号令 | 前往后果构造体 | 功用 |
| RKNN_QUERY_IN_OUT_NUM | rknn_input_output_num | 查询输出输入tensor个数。 |
| RKNN_QUERY_INPUT_ATTR | rknn_tensor_attr | 查询输出tensor属性。 |
| RKNN_QUERY_OUTPUT_ATTR | rknn_tensor_attr | 查询输入tensor属性。 |
| RKNN_QUERY_PERF_DETAIL | rknn_perf_detail | 查询收集各层运转工夫,需求挪用rknn_init接心时,设置RKNN_FLAG_COLLECT_PERF_MASK标记才干失效。 |
| RKNN_QUERY_PERF_RUN | rknn_perf_run | 查询推理模子(没有包括设置输出/输入)的耗时,单元是微秒。 |
| RKNN_QUERY_SDK_VERSION | rknn_sdk_version | 查询SDK版本。 |
| RKNN_QUERY_MEM_SIZE | rknn_mem_size | 查询分派给权重战收集两头tensor的内存巨细。 |
| RKNN_QUERY_CUSTOM_STRING | rknn_custom_string | 查询RKNN模子外面的用户自界说字符串疑息。 |
| RKNN_QUERY_NATIVE_INPUT_ATTR | rknn_tensor_attr | 运用整拷贝API接心时,查询本死输出tensor属性,它是NPU间接读与的模子输出属性。 |
| RKNN_QUERY_NATIVE_OUTPUT_ATTR | rknn_tensor_attr | 运用整拷贝API接心时,查询本死输入tensor属性,它是NPU间接输入的模子输入属性。 |
| RKNN_QUERY_NATIVE_NC1HWC2_INPUT_ATTR | rknn_tensor_attr | 运用整拷贝API接心时,查询本死输出tensor属性,它是NPU间接读与的模子输出属性取RKNN_QUERY_NATIVE_INPUT_ATTR查询后果分歧。 |
| RKNN_QUERY_NATIVE_NC1HWC2_OUTPUT_ATTR | rknn_tensor_attr | 运用整拷贝API接心时,查询本死输入tensor属性,它是NPU间接输入的模子输入属取RKNN_QUERY_NATIVE_OUTPUT_ATTR查询后果分歧性。 |
| RKNN_QUERY_NATIVE_NHWC_INPUT_ATTR | rknn_tensor_attr | 运用整拷贝API接心时,查询本死输出 tensor属性取RKNN_QUERY_NATIVE_INPUT_ATTR查询后果分歧 。 |
| RKNN_QUERY_NATIVE_NHWC_OUTPUT_ATTR | rknn_tensor_attr | 运用整拷贝API接心时,查询本死输入NHWC tensor属性。 |
| RKNN_QUERY_DEVICE_MEM_INFO | rknn_tensor_mem | 查询模子buffer的内存属性。 |
| RKNN_QUERY_INPUT_DYNAMIC_RANGE | rknn_input_range | 运用撑持静态外形RKNN模子时,查询模子撑持输出外形数目、列表、外形对应的数据规划战称号等疑息。 |
| RKNN_QUERY_CURRENT_INPUT_ATTR | rknn_tensor_attr | 运用撑持静态外形RKNN模子时,查询模子以后推理所运用的输出属性。 |
| RKNN_QUERY_CURRENT_OUTPUT_ATTR | rknn_tensor_attr | 运用撑持静态外形RKNN模子时,查询模子以后推理所运用的输入属性。 |
| RKNN_QUERY_CURRENT_NATIVE_INPUT_ATTR | rknn_tensor_attr | 运用撑持静态外形RKNN模子时,查询模子以后推理所运用的NPU本死输出属性。 |
| RKNN_QUERY_CURRENT_NATIVE_OUTPUT_ATTR | rknn_tensor_att | 运用撑持静态外形RKNN模子时,查询模子以后推理所运用的NPU本死输入属性。 |
各个指令用法的具体阐明,以下:
1.查询SDK版本
传进RKNN_QUERY_SDK_VERSION号令能够查询RKNN SDK的版本疑息。此中需求先创立rknn_sdk_version构造体工具。
示例代码以下:
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version));
printf("sdk api version: %sn", version.api_version);
printf("driver version: %sn", version.drv_version);
2. 查询输出输入tensor个数
正在rknn_init接心挪用终了后,传进RKNN_QUERY_IN_OUT_NUM号令能够查询模子输出输入tensor的个数。此中需求先创立rknn_input_output_num构造体工具。
示例代码以下:
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
printf("model input num: %d, output num: %dn", io_num.n_input, io_num.n_output);
3. 查询输出tensor属性(用于通用API接心)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_INPUT_ATTR号令能够查询模子输出tensor的属性。此中需求先创立rknn_tensor_attr构造体工具 (留意:RV1106/RV1103/RV1106B/RV1103B/RK2118 查询出去的tensor是本初输出native的tensor) 。
示例代码以下:
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
}
4. 查询输入tensor属性(用于通用API接心)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_OUTPUT_ATTR号令能够查询模子输入tensor的属性。此中需求先创立rknn_tensor_attr构造体工具。
示例代码以下:
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
}
5. 查询模子推理的逐层耗时
正在rknn_run接心挪用终了后,rknn_query接口授进RKNN_QUERY_PERF_DETAIL能够查询收集推理时逐层的耗时,单元是微秒。运用该号令的条件是,正在rknn_init接心的flag参数需求包括RKNN_FLAG_COLLECT_PERF_MASK标记。
示例代码以下:
rknn_context ctx; int ret = rknn_init(&ctx, model_data, model_data_size, RKNN_FLAG_COLLECT_PERF_MASK, NULL); ... ret = rknn_run(ctx,NULL); ... rknn_perf_detail perf_detail; ret = rknn_query(ctx, RKNN_QUERY_PERF_DETAIL, &perf_detail, sizeof(perf_detail));
6. 查询模子推理的总耗时
正在rknn_run接心挪用终了后,rknn_query接口授进RKNN_QUERY_PERF_RUN能够查询上模子推理(没有包括设置输出/输入)的耗时,单元是微秒。
示例代码以下:
rknn_context ctx; int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL); ... ret = rknn_run(ctx,NULL); ... rknn_perf_run perf_run; ret = rknn_query(ctx, RKNN_QUERY_PERF_RUN, &perf_run, sizeof(perf_run));
7. 查询模子的内存占用状况
正在rknn_init接心挪用终了后,当用户需求自止分派收集的内存时,rknn_query接口授进RKNN_QUERY_MEM_SIZE能够查询模子的权重、收集两头tensor的内存(没有包罗输出战输入)、推演模子所用的一切DMA内存的和SRAM内存(假如sram出开或许出有此项功用则为0)的占用状况。运用该号令的条件是正在rknn_init接心的flag参数需求包括RKNN_FLAG_MEM_ALLOC_OUTSIDE标记。
示例代码以下:
rknn_context ctx; int ret = rknn_init(&ctx, model_data, model_data_size, RKNN_FLAG_MEM_ALLOC_OUTSIDE , NULL); rknn_mem_size mem_size; ret = rknn_query(ctx, RKNN_QUERY_MEM_SIZE, &mem_size, sizeof(mem_size));
8. 查询模子顶用户自界说字符串
正在rknn_init接心挪用终了后,当用户需求查询死成RKNN模子时参加的自界说字符串,rknn_query接口授进RKNN_QUERY_CUSTOM_STRING能够获得该字符串。比方,正在转换RKNN模子时,用户挖进“RGB”的自界说字符去标识RKNN模子输出是RGB格局三通讲图象而没有是BGR格局三通讲图象,正在运转时则依据查询到的“RGB”疑息将数据转换成RGB图象。
示例代码以下:
rknn_context ctx; int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL); rknn_custom_string custom_string; ret = rknn_query(ctx, RKNN_QUERY_CUSTOM_STRING, &custom_string, sizeof(custom_string));
9. 查询本死输出tensor属性(用于整拷贝API接心)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_NATIVE_INPUT_ATTR号令(同RKNN_QUERY_NATIVE_NC1HWC2_INPUT_ATTR)能够查询模子本死输出tensor的属性。此中需求先创立rknn_tensor_attr构造体工具。
示例代码以下:
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
}
10. 查询本死输入tensor属性(用于整拷贝API接心)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_NATIVE_OUTPUT_ATTR号令(同RKNN_QUERY_NATIVE_NC1HWC2_OUTPUT_ATTR)能够查询模子本死输入tensor的属性。此中需求先创立rknn_tensor_attr构造体工具。
示例代码以下:
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
}
11. 查询NHWC格局本死输出tensor属性(用于整拷贝API接心)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_NATIVE_NHWC_INPUT_ATTR号令能够查询模子NHWC格局输出tensor的属性。此中需求先创立rknn_tensor_attr构造体工具。
示例代码以下:
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for (int i = 0; i < io_num.n_input; i++) {
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_NHWC_INPUT_ATTR,
&(input_attrs[i]), sizeof(rknn_tensor_attr));
}
12. 查询NHWC格局本死输入tensor属性(用于整拷贝API接心)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_NATIVE_NHWC_OUTPUT_ATTR号令能够查询模子NHWC格局输入tensor的属性。此中需求先创立rknn_tensor_attr构造体工具。
示例代码以下:
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_NATIVE_NHWC_OUTPUT_ATTR,
&(output_attrs[i]), sizeof(rknn_tensor_attr));
}
13. 查询模子buffer的内存属性(注:仅RV1106/RV1103/RV1106B/RV1103B/RK2118撑持该查询)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_DEVICE_MEM_INFO号令能够查询Runtime外部开拓的模子buffer的包罗fd、物理地点等属性。
rknn_tensor_mem mem_info; memset(&mem_info, 0, sizeof(mem_info)); ret = rknn_query(ctx, RKNN_QUERY_DEVICE_MEM_INFO, &mem_info, sizeof(mem_info));
14. 查询RKNN模子撑持的静态输出外形疑息(注:RV1106/RV1103/RV1106B/RV1103B/RK2118没有撑持该接心)
正在rknn_init接心挪用终了后,传进RKNN_QUERY_INPUT_DYNAMIC_RANGE号令能够查询模子撑持的输出外形疑息,包括输出外形个数 、输出外形列表、输出外形对应的规划战称号等疑息。此中需求先创立rknn_input_range构造体工具。
示例代码以下:
rknn_input_range dyn_range[io_num.n_input];
memset(dyn_range, 0, io_num.n_input * sizeof(rknn_input_range));
for (uint32_t i = 0; i < io_num.n_input; i++) {
dyn_range[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_DYNAMIC_RANGE,
&dyn_range[i], sizeof(rknn_input_range));
}
15. 查询RKNN模子以后运用的输出静态外形
正在rknn_set_input_shapes接心挪用终了后,传进RKNN_QUERY_CURRENT_INPUT_ATTR号令能够查询模子以后运用的输出属性疑息。此中需求先创立rknn_tensor_attr构造体(注:RV1106/RV1103/RV1106B/RV1103B/RK2118没有撑持该号令)。
示例代码以下:
rknn_tensor_attr cur_input_attrs[io_num.n_input];
memset(cur_input_attrs, 0, io_num.n_input * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_input; i++) {
cur_input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_INPUT_ATTR,
&(cur_input_attrs[i]), sizeof(rknn_tensor_attr));
}
16. 查询RKNN模子以后运用的输入静态外形
正在rknn_set_input_shapes接心挪用终了后,传进RKNN_QUERY_CURRENT_OUTPUT_ATTR号令能够查询模子以后运用的输入属性疑息。此中需求先创立rknn_tensor_attr构造体(注:RV1106/RV1103/RV1106B/RV1103B/RK2118没有撑持该号令)。
示例代码以下:
rknn_tensor_attr cur_output_attrs[io_num.n_output];
memset(cur_output_attrs, 0, io_num.n_output * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_output; i++) {
cur_output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_OUTPUT_ATTR,
&(cur_output_attrs[i]), sizeof(rknn_tensor_attr));
}
17. 查询RKNN模子以后运用的本死输出静态外形
正在rknn_set_input_shapes接心挪用终了后,传进RKNN_QUERY_CURRENT_NATIVE_INPUT_ATTR号令能够查询模子以后运用的本死输出属性疑息。此中需求先创立rknn_tensor_attr构造体(注:RV1106/RV1103/RV1106B/RV1103B/RK2118没有撑持该号令)。
示例代码以下:
rknn_tensor_attr cur_input_attrs[io_num.n_input];
memset(cur_input_attrs, 0, io_num.n_input * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_input; i++) {
cur_input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_NATIVE_INPUT_ATTR,
&(cur_input_attrs[i]), sizeof(rknn_tensor_attr));
}
18. 查询RKNN模子以后运用的本死输入静态外形
正在rknn_set_input_shapes接心挪用终了后,传进RKNN_QUERY_CURRENT_NATIVE_OUTPUT_ATTR号令能够查询模子以后运用的本死输入属性疑息。此中需求先创立rknn_tensor_attr构造体(注:RV1106/RV1103/RV1106B/RV1103B/RK2118没有撑持该号令)。
示例代码以下:
rknn_tensor_attr cur_output_attrs[io_num.n_output];
memset(cur_output_attrs, 0, io_num.n_output * sizeof(rknn_tensor_attr));
for (uint32_t i = 0; i < io_num.n_output; i++) {
cur_output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_CURRENT_NATIVE_OUTPUT_ATTR,
&(cur_output_attrs[i]), sizeof(rknn_tensor_attr));
}
7.2.2.7 rknn_inputs_set
经过rknn_inputs_set函数能够设置模子的输出数据。该函数可以撑持多个输出,此中每一个输出是rknn_input构造体工具,正在传进之前用户需求设置该工具,注:RV1106/RV1103/RV1106B/RV1103B/RK2118没有撑持该接心。
| API | rknn_inputs_set |
| 功用 | 设置模子输出数据。 |
| 参数 | rknn_context context:rknn_context工具。 |
| uint32_t n_inputs:输出数据个数。 | |
| rknn_input inputs[]:输出数据数组,数组每一个元素是rknn_input构造体工具。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_input inputs[1]; memset(inputs, 0, sizeof(inputs)); inputs[0].index = 0; inputs[0].type = RKNN_TENSOR_UINT8; inputs[0].size = img_width*img_height*img_channels; inputs[0].fmt = RKNN_TENSOR_NHWC; inputs[0].buf = in_data; inputs[0].pass_through = 0; ret = rknn_inputs_set(ctx, 1, inputs);
7.2.2.8 rknn_run
rknn_run函数将履行一次模子推理,挪用之前需求先经过rknn_inputs_set函数或许整拷贝的接心设置输出数据。
| API | rknn_run |
| 功用 | 履行一次模子推理。 |
| 参数 | rknn_context context:rknn_context工具。 |
| rknn_run_extend* extend:保存扩大,以后出有运用,传进NULL便可。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
ret = rknn_run(ctx, NULL);
7.2.2.9 rknn_outputs_get
rknn_outputs_get函数能够获得模子推理的输入数据。该函数可以一次获得多个输入数据。此中每一个输入是rknn_output构造体工具,正在函数挪用之前需求顺次创立并设置每一个rknn_output工具。
关于输入数据的buffer寄存能够采取两种体例:一种是用户自止请求战开释,此时rknn_output工具的is_prealloc需求设置为1,而且将buf指针指背用户请求的buffer;另外一种是由rknn去停止分派,此时rknn_output工具的is_prealloc设置为0便可,函数履行以后buf将指背输入数据。注:RV1106/RV1103/RV1106B/RV1103B/RK2118没有撑持该接心
| API | rknn_outputs_get |
| 功用 | 获得模子推理输入。 |
| 参数 | rknn_context context:rknn_context工具。 |
| uint32_t n_outputs:输入数据个数。 | |
| rknn_output outputs[]:输入数据的数组,此中数组每一个元素为rknn_output构造体工具,代表模子的一个输入。 | |
| rknn_output_extend* extend:保存扩大,以后出有运用,传进NULL便可。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].index = i;
outputs[i].is_prealloc = 0;
outputs[i].want_float = 1;
}
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
7.2.2.10 rknn_outputs_release
rknn_outputs_release函数将开释rknn_outputs_get函数失掉的输入的相干资本。
| API | rknn_outputs_release |
| 功用 | 开释rknn_output工具。 |
| 参数 | rknn_context context:rknn_context工具。 |
| uint32_t n_outputs:输入数据个数。 | |
| rknn_output outputs[]:要烧毁的rknn_output数组。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
7.2.2.11 rknn_create_mem_from_phys
当用户需求本人分派内存让NPU运用时,经过rknn_create_mem_from_phys函数能够创立一个rknn_tensor_mem构造体并失掉它的指针,该函数经过传进物理地点、实拟地点和巨细,内部内存相干的疑息会赋值给rknn_tensor_mem构造体。
| API | rknn_create_mem_from_phys |
| 功用 | 经过物理地点创立rknn_tensor_mem构造体并分派内存。 |
| 参数 | rknn_context context:rknn_context工具。 |
| uint64_t phys_addr:内存的物理地点。 | |
| void *virt_addr:内存的实拟地点。 | |
| uint32_t size:内存的巨细。 | |
| 前往值 | rknn_tensor_mem*: tensor内存疑息构造体指针。 |
示例代码以下:
//suppose we have got buffer information as input_phys, input_virt and size rknn_tensor_mem* input_mems [1]; input_mems[0] = rknn_create_mem_from_phys(ctx, input_phys, input_virt, size);
7.2.2.12 rknn_create_mem_from_fd
当用户要本人分派内存让NPU运用时,rknn_create_mem_from_fd函数能够创立一个rknn_tensor_mem构造体并失掉它的指针,该函数经过传进文件描绘符fd、偏偏移、实拟地点和巨细,内部内存相干的疑息会赋值给rknn_tensor_mem构造体。
| API | rknn_create_mem_from_fd |
| 功用 | 经过文件描绘符创立rknn_tensor_mem构造体。 |
| 参数 | rknn_context context:rknn_context工具。 |
| int32_t fd:内存的文件描绘符。 | |
| void *virt_addr:内存的实拟地点,fd对应的内存的尾地点。 | |
| uint32_t size:内存的巨细。 | |
| int32_t offset:内存绝对于文件描绘符战实拟地点的偏偏移量。 | |
| 前往值 | rknn_tensor_mem*: tensor内存疑息构造体指针。 |
示例代码以下:
//suppose we have got buffer information as input_fd, input_virt and size rknn_tensor_mem* input_mems [1]; input_mems[0] = rknn_create_mem_from_fd(ctx, input_fd, input_virt, size, 0);
7.2.2.13 rknn_create_mem
当用户要NPU外部分派内存时,rknn_create_mem函数能够分派用户指定的内存巨细,并前往一个rknn_tensor_mem构造体。
| API | rknn_create_mem |
| 功用 | 创立rknn_tensor_mem构造体并分派内存。 |
| 参数 | rknn_context context:rknn_context工具。 |
| uint32_t size:内存的巨细。 | |
| 前往值 | rknn_tensor_mem*: tensor内存疑息构造体指针。 |
示例代码以下:
//suppose we have got buffer size rknn_tensor_mem* input_mems [1]; input_mems[0] = rknn_create_mem(ctx, size);
7.2.2.14 rknn_create_mem2
当用户要NPU外部分派内存时,rknn_create_mem2函数能够分派用户指定的内存巨细及内存范例,并前往一个rknn_tensor_mem构造体。
| API | rknn_create_mem2 |
| 功用 | 创立rknn_tensor_mem构造体并分派内存。 |
| 参数 | rknn_context context:rknn_context工具。 |
| uint64_t size:内存的巨细。 | |
|
uint64_t alloc_flags: 节制内存能否是cacheable的。 RKNN_FLAG_MEMORY_CACHEABLE:创立cacheable内存 RKNN_FLAG_MEMORY_NON_CACHEABLE: 创立non -cacheable内存 RKNN_FLAG_MEMORY_FLAGS_DEFAULT:同RKNN_FLAG_MEMORY_CACHEABLE |
|
| 前往值 | rknn_tensor_mem*: tensor内存疑息构造体指针。 |
rknn_create_mem2取rknn_create_mem的次要区分是rknn_create_mem2带了一个alloc_flags,能够指定分派的内存能否cacheable的,而rknn_create_mem不克不及指定,默许便是cacheable。
示例代码以下:
//suppose we have got buffer size rknn_tensor_mem* input_mems [1]; input_mems[0] = rknn_create_mem2(ctx, size, RKNN_FLAG_MEMORY_NON_CACHEABLE);
7.2.2.15 rknn_destroy_mem
rknn_destroy_mem函数会烧毁rknn_tensor_mem构造体,用户分派的内存需求自止开释。
| API | rknn_destroy_mem |
| 功用 | 烧毁rknn_tensor_mem构造体。 |
| 参数 | rknn_context context:rknn_context工具。 |
| rknn_tensor_mem*:tensor内存疑息构造体指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_tensor_mem* input_mems [1]; int ret = rknn_destroy_mem(ctx, input_mems[0]);
7.2.2.16 rknn_set_weight_mem
假如用户本人为收集权重分派内存,初初化响应的rknn_tensor_mem构造体后,正在挪用rknn_run前,经过rknn_set_weight_mem函数可让NPU运用该内存。
| API | rknn_set_weight_mem |
| 功用 | 设置包括权重内存疑息的rknn_tensor_mem构造体。 |
| 参数 | rknn_context context:rknn_context工具。 |
| rknn_tensor_mem*:权重tensor内存疑息构造体指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_tensor_mem* weight_mems [1]; int ret = rknn_set_weight_mem(ctx, weight_mems[0]);
7.2.2.17 rknn_set_internal_mem
假如用户本人为收集两头tensor分派内存,初初化响应的rknn_tensor_mem构造体后,正在挪用rknn_run前,经过rknn_set_internal_mem函数可让NPU运用该内存。
| API | rknn_set_internal_mem |
| 功用 | 设置包括两头tensor内存疑息的rknn_tensor_mem构造体。 |
| 参数 | rknn_context context:rknn_context工具。 |
| rknn_tensor_mem*:模子两头tensor内存疑息构造体指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_tensor_mem* internal_tensor_mems [1]; int ret = rknn_set_internal_mem(ctx, internal_tensor_mems[0]);
7.2.2.18 rknn_set_io_mem
假如用户本人为收集输出/输入tensor分派内存,初初化响应的rknn_tensor_mem构造体后,正在挪用rknn_run前,经过rknn_set_io_mem函数可让NPU运用该内存。
| API | rknn_set_io_mem |
| 功用 | 设置包括模子输出/输入内存疑息的rknn_tensor_mem构造体。 |
| 参数 | rknn_context context:rknn_context工具。 |
| rknn_tensor_mem*:输出/输入tensor内存疑息构造体指针。 | |
| rknn_tensor_attr *: 输出/输入tensor的属性。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_tensor_attr output_attrs[1]; rknn_tensor_mem* output_mems[1]; ret = rknn_query(ctx, RKNN_QUERY_NATIVE_OUTPUT_ATTR, &(output_attrs[0]), sizeof(rknn_tensor_attr)); output_mems[0] = rknn_create_mem(ctx, output_attrs[0].size_with_stride); rknn_set_io_mem(ctx, output_mems[0], &output_attrs[0]);
7.2.2.19 rknn_set_input_shape(deprecated)
该接心曾经烧毁,请运用rknn_set_input_shapes接心绑定输出外形。以后版本不成用,如要持续运用该接心,请运用1.5.0版本SDK并参考1.5.0版本的运用指北文档。
7.2.2.20 rknn_set_input_shapes
关于静态外形输出RKNN模子,正在推理前必需指定以后运用的输出外形。该接口授进输出个数战rknn_tensor_attr数组,包括了每一个输出外形战对应的数据规划疑息,将每一个rknn_tensor_attr构造体工具的索引、称号、外形(dims)战内存规划疑息(fmt)必需挖充,rknn_tensor_attr构造体其他成员无需设置。正在运用该接心前,可先经过rknn_query函数查询RKNN模子撑持的输出外形数目战静态外形列表,请求输出数据的外形正在模子撑持的输出外形列表中。初度运转或每次切换新的输出外形,需求挪用该接心设置新的外形,不然,没有需求反复挪用该接心。
| API | rknn_set_input_shapes |
| 功用 | 设置模子以后运用的输出外形。 |
| 参数 | rknn_context context:rknn_context工具。 |
| uint32_t n_inputs:输出Tensor的数目。 | |
| rknn_tensor_attr *: 输出tensor的属性数组指针,通报一切输出的外形疑息,用户需求设置每一个输出属性构造体中的index、name、dims、fmt、n_dims成员,其他成员无需设置。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
for (int i = 0; i < io_num.n_input; i++) {
for (int j = 0; j < input_attrs[i].n_dims; ++j) {
//使用第一个动态输入形状
input_attrs[i].dims[j] = dyn_range[i].dyn_range[0][j];
}
}
ret = rknn_set_input_shapes(ctx, io_num.n_input, input_attrs);
if (ret < 0) {
fprintf(stderr, "rknn_set_input_shapes error! ret=%dn", ret);
return -1;
}
7.2.2.21 rknn_mem_sync
rknn_create_mem函数创立的内存默许是带cacheable标记的,关于带cacheable标记创立的内存,正在被CPU战NPU同时运用时,因为cache行动会招致数据分歧性成绩。该接心用于同步一块带cacheable标记创立的内存,包管CPU战NPU拜访那块内存的数据是分歧的。
| API | rknn_mem_sync |
| 功用 | 同步CPU cache战DDR数据。 |
| 参数 | rknn_context context:rknn_context工具。 |
| rknn_tensor_mem* mem:tensor内存疑息构造体指针。 | |
|
rknn_mem_sync_mode mode: 暗示革新CPU cache战DDR数据的形式。 RKNN_MEMORY_SYNC_TO_DEVICE:暗示CPU cache数据同步到DDR中,凡是用于CPU写进内存后,NPU拜访相反内存前运用该形式将cache中的数据写回DDR。 RKNN_MEMORY_SYNC_FROM_DEVICE:暗示DDR数据同步到CPU cache,凡是用于NPU写进内存后,运用该形式让下次CPU拜访相反内存时,cache数据有效,CPU从DDR从头读与数据。 RKNN_MEMORY_SYNC_BIDIRECTIONAL:暗示CPU cache数据同步到DDR同时令CPU 从头从DDR读与数据。 |
|
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
ret =rknn_mem_sync(ctx, &outputs[0].mem,
RKNN_MEMORY_SYNC_FROM_DEVICE);
if (ret < 0) {
fprintf(stderr, " rknn_mem_sync error! ret=%dn", ret);
return -1;
}
7.2.3 矩阵乘法数据构造界说
7.2.3.1 rknn_matmul_info
rknn_matmul_info暗示用于履行矩阵乘法的规格疑息,它包括了矩阵乘法的范围、输出战输入矩阵的数据范例战内存排布。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| M | int32_t | A矩阵的止数 |
| K | int32_t | A矩阵的列数 |
| N | int32_t | B矩阵的列数 |
| type | rknn_matmul_type |
输出输入矩阵的数据范例: RKNN_FLOAT16_MM_FLOAT16_TO_FLOAT32:暗示矩阵A战B是float16范例,矩阵C是float范例; RKNN_INT8_MM_INT8_TO_INT32:暗示矩阵A战B是int8范例,矩阵C是int32范例; RKNN_INT8_MM_INT8_TO_INT8:暗示矩阵A、B战C是int8范例; RKNN_FLOAT16_MM_FLOAT16_TO_FLOAT16:暗示矩阵A、B战C是float16范例; RKNN_FLOAT16_MM_INT8_TO_FLOAT32:暗示矩阵A是float16范例,矩阵B是int8范例,矩阵C是float范例; RKNN_FLOAT16_MM_INT8_TO_FLOAT16:暗示矩阵A是float16范例,矩阵B是int8范例,矩阵C是float16范例; RKNN_FLOAT16_MM_INT4_TO_FLOAT32:暗示矩阵A是float16范例,矩阵B是int4范例,矩阵C是float范例; RKNN_FLOAT16_MM_INT4_TO_FLOAT16:暗示矩阵A是float16范例,矩阵B是int4范例,矩阵C是float16范例; RKNN_INT8_MM_INT8_TO_FLOAT32:暗示矩阵A战B是int8范例,矩阵C是float范例; RKNN_INT4_MM_INT4_TO_INT16:暗示矩阵A战B是int4范例,矩阵C是int16范例; RKNN_INT8_MM_INT4_TO_INT32:暗示矩阵A是int8范例,B是int4范例,矩阵C是int32范例 |
| B_layout | int16_t |
矩阵B的数据陈列体例。 RKNN_MM_LAYOUT_NORM:暗示矩阵B依照本初外形陈列 ,即KxN的外形陈列; RKNN_MM_LAYOUT_NATIVE:暗示矩阵B依照下功能外形陈列; RKNN_MM_LAYOUT_TP_NORM:暗示矩阵B依照Transpose后的外形陈列,即NxK的外形陈列 |
| B_quant_type | int16_t |
矩阵B的量化体例范例。 RKNN_QUANT_TYPE_PER_LAYER_SYM:暗示矩阵B依照Per-Layer体例对称量化; RKNN_QUANT_TYPE_PER_LAYER_ASYM:暗示矩阵B依照Per-Layer体例非对称量化; RKNN_QUANT_TYPE_PER_CHANNEL_SYM:暗示矩阵B依照Per-Channel体例对称量化; RKNN_QUANT_TYPE_PER_CHANNEL_ASYM:暗示矩阵B依照Per-Channel体例非对称量化; RKNN_QUANT_TYPE_PER_GROUP_SYM:暗示矩阵B依照Per-Group体例对称量化; RKNN_QUANT_TYPE_PER_GROUP_ASYM:暗示矩阵B依照Per-Group体例非对称量化 |
| AC_layout | int16_t |
矩阵A战C的数据陈列体例。 RKNN_MM_LAYOUT_NORM:暗示矩阵A战C依照本初外形陈列; RKNN_MM_LAYOUT_NATIVE:暗示矩阵A战C依照下功能外形陈列 |
| AC_quant_type | int16_t |
矩阵A战C的量化体例范例。 RKNN_QUANT_TYPE_PER_LAYER_SYM:暗示矩阵A战C依照Per-Layer体例对称量化; RKNN_QUANT_TYPE_PER_LAYER_ASYM:暗示矩阵A战C依照Per-Layer体例非对称量化 |
| iommu_domain_id | int32_t |
矩阵高低文地点的IOMMU地点空间域的索引。IOMMU地点空间取高低文逐个对应,每一个IOMMU地点空间巨细为 4GB。该参数次要用于矩阵A、B战C的参数规格较年夜,某个域内NPU分派的内存超越4GB当前需切换另外一个域时使 用。 |
| group_size | int16_t | 一个组的元素数目,仅分组量化开启后失效。 |
| reserved | int8_t[] | 预留字段 |
7.2.3.2 rknn_matmul_tensor_attr
rknn_matmul_tensor_attr暗示每一个矩阵tensor的属性,它包括了矩阵的名字、外形、巨细战数据范例。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| name | char[] | 矩阵的名字 |
| n_dims | uint32_t | 矩阵的维度个数 |
| dims | uint32_t[] | 矩阵的外形 |
| size | uint32_t | 矩阵的巨细,以字节为单元 |
| ype | rknn_tensor_type | 矩阵的数据范例 |
7.2.3.3 rknn_matmul_io_attr
rknn_matmul_io_attr暗示矩阵一切输出战输入tensor的属性,它包括了矩阵A、B战C的属性。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| A | rknn_matmul_tensor_attr | 矩阵A的tensor属性 |
| B | rknn_matmul_tensor_attr | 矩阵B的tensor属性 |
| C | rknn_matmul_tensor_attr | 矩阵C的tensor属性 |
7.2.3.4 rknn_quant_params
rknn_quant_params暗示矩阵的量化参数,包罗name和scale战zero_point数组的指针战少度,name用去标识矩阵的称号,它能够从初初化矩阵高低文时失掉的rknn_matmul_io_attr构造体中获得。构造体界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| name | char[] | 矩阵的名字 |
| scale | float* | 矩阵的scale数组指针 |
| scale_len | int32_t | 矩阵的scale数组少度 |
| zp | int32_t* | 矩阵的zero_point数组指针 |
| zp_len | int32_t | 矩阵的zero_point数组少度 |
7.2.3.5 rknn_matmul_shape
rknn_matmul_shape暗示某个特定shape的矩阵乘法的M、K战N,正在初初化静态shape的矩阵乘法高低文时,需求供给shape的数目,并运用rknn_matmul_shape构造体数组暗示一切的输出的shape。构造体界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| M | int32_t | 矩阵A的止数 |
| K | int32_t | 矩阵A的列数 |
| N | int32_t | 矩阵B的列数 |
7.2.4 矩阵乘法API阐明
7.2.4.1 rknn_matmul_create
该函数的功用是依据传进的矩阵乘律例格等疑息,完成矩阵乘法高低文的初初化,并前往输出战输入tensor的外形、巨细战数据范例等疑息。
| API | rknn_matmul_create |
| 功用 | 初初化矩阵乘法高低文。 |
| 参数 | rknn_matmul_ctx* ctx:矩阵乘法高低文指针。 |
| rknn_matmul_info* info:矩阵乘法的规格疑息构造体指针。 | |
| rknn_matmul_io_attr* io_attr:矩阵乘法输出战输入tensor属性构造体指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_matmul_info info;
memset(&info, 0, sizeof(rknn_matmul_info));
info.M = 4;
info.K = 64;
info.N = 32;
info.type = RKNN_INT8_MM_INT8_TO_INT32;
info.B_layout = RKNN_MM_LAYOUT_NORM;
info.AC_layout = RKNN_MM_LAYOUT_NORM;
rknn_matmul_io_attr io_attr;
memset(&io_attr, 0, sizeof(rknn_matmul_io_attr));
int ret = rknn_matmul_create(&ctx, &info, &io_attr);
if (ret < 0) {
printf("rknn_matmul_create fail! ret=%dn", ret);
return -1;
}
7.2.4.2 rknn_matmul_set_io_mem
该函数用于设置矩阵乘法运算的输出/输入内存。正在挪用该函数前,先运用rknn_create_mem接心创立的rknn_tensor_mem构造体指针,接着将其取rknn_matmul_create函数前往的矩阵A、B或C的rknn_matmul_tensor_attr构造体指针传进该函数,把输出战输入内存设置到矩阵乘法高低文中。正在挪用该函数前,要依据rknn_matmul_info中设置装备摆设的内存排布预备好矩阵A战矩阵B的数据。
| API | rknn_matmul_set_io_mem |
| 功用 | 设置矩阵乘法的输出/输入内存。 |
| 参数 | rknn_matmul_ctx ctx:矩阵乘法高低文。 |
| rknn_tensor_mem* mem:tensor内存疑息构造体指针。 | |
| rknn_matmul_tensor_attr* attr:矩阵乘法输出战输入tensor属性构造体指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
// Create A
rknn_tensor_mem* A = rknn_create_mem(ctx, io_attr.A.size);
if (A == NULL) {
printf("rknn_create_mem fail!n");
return -1;
}
memset(A->virt_addr, 1, A->size);
rknn_matmul_io_attr io_attr;
memset(&io_attr, 0, sizeof(rknn_matmul_io_attr));
int ret = rknn_matmul_create(&ctx, &info, &io_attr);
if (ret < 0) {
printf("rknn_matmul_create fail! ret=%dn", ret);
return -1;
}
// Set A
ret = rknn_matmul_set_io_mem(ctx, A, &io_attr.A);
if (ret < 0) {
printf("rknn_matmul_set_io_mem fail! ret=%dn", ret);
return -1;
}
7.2.4.3 rknn_matmul_set_core_mask
该函数用于设置矩阵乘法运算时可用的NPU中心(仅撑持RK3588战RK3576仄台)。正在挪用该函数前,需求先经过rknn_matmul_create函数初初化矩阵乘法高低文。可经过该函数设置的掩码值,指定需求运用的中心,以进步矩阵乘法运算的功能战效力。
| API | rknn_matmul_set_core_mask |
| 功用 | 设置矩阵乘法运算的NPU中心掩码。 |
| 参数 | rknn_matmul_ctx ctx:矩阵乘法高低文。 |
| rknn_core_mask core_mask:矩阵乘法运算的NPU中心掩码值,用于指定可用的NPU中心。掩码的每位代表一个中心,假如对应位为1,则暗示该中心可用;不然,暗示该中心不成用(具体掩码阐明睹rknn_set_core_mask API参数)。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_matmul_set_core_mask(ctx, RKNN_NPU_CORE_AUTO);
7.2.4.4 rknn_matmul_set_quant_params
rknn_matmul_set_quant_params用于设置每一个矩阵的量化参数,撑持Per-Channel量化、Per-Layer量化战PerGroup量化体例的量化参数设置。当运用Per-Group量化时,rknn_quant_params中的scale战zp数组的少度即是N*K/group_size。当运用Per-Channel量化时,rknn_quant_params中的scale战zp数组的少度即是N。当运用Per-Layer量化时,rknn_quant_params中的scale战zp数组的少度为1。正在rknn_matmul_run之前挪用此接心设置一切矩阵的量化参数。假如没有挪用此接心,则默许量化体例为Per-Layer量化,scale=1.0,zero_point=0。
| API | rknn_matmul_set_quant_params |
| 功用 | 设置矩阵的量化参数。 |
| 参数 | rknn_matmul_ctx ctx:矩阵乘法高低文。 |
| rknn_quant_params* params: 矩阵的量化参数疑息。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
rknn_quant_params params_a; memcpy(params_a.name, io_attr.A.name, RKNN_MAX_NAME_LEN); params_a.scale_len = 1; params_a.scale = (float *)malloc(params_a.scale_len * sizeof(float)); params_a.scale[0] = 0.2; params_a.zp_len = 1; params_a.zp = (int32_t *)malloc(params_a.zp_len * sizeof(int32_t)); params_a.zp[0] = 0; rknn_matmul_set_quant_params(ctx, ¶ms_a);
7.2.4.5 rknn_matmul_get_quant_params
rknn_matmul_get_quant_params用于rknn_matmul_type范例即是RKNN_INT8_MM_INT8_TO_INT32而且Per-Channel量化体例时,获得矩阵B一切通讲scale回一化后的scale值,获得的scale值战A的本初scale值相乘能够失掉C的scale值。能够用于正在矩阵C出有实在scale时,远似计较失掉C的scale。
| API | rknn_matmul_get_quant_params |
| 功用 | 获得矩阵B的量化参数。 |
| 参数 | rknn_matmul_ctx ctx:矩阵乘法高低文。 |
| rknn_quant_params* params: 矩阵B的量化参数疑息。 | |
| float* scale: 矩阵B的scale指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
float b_scale; rknn_matmul_get_quant_params(ctx, ¶ms_b, &b_scale);
7.2.4.6 rknn_matmul_create_dyn_shape(deprecated)
该接心已烧毁,改用rknn_matmul_create_dynamic_shape接心。
7.2.4.7 rknn_matmul_create_dynamic_shape
rknn_matmul_create_dynamic_shape用于创立静态shape矩阵乘法高低文,该接心需求传进rknn_matmul_info构造体、shape数目和对应的shape数组,shape数组会记载多个M、K战N值。正在初初化胜利后,会失掉
rknn_matmul_io_attr的数组,数组中包括了一切的输出输入矩阵的shape、巨细战数据范例等疑息。今朝撑持设置多个分歧的M,K战N。
| API | rknn_matmul_create_dynamic_shape |
| 功用 | 初初化静态shape矩阵乘法的高低文。 |
| 参数 | rknn_matmul_ctx *ctx:矩阵乘法高低文指针。 |
| rknn_matmul_info* info:矩阵乘法的规格疑息构造体指针。此中M、K战N没有需求设置。 | |
| int shape_num:矩阵高低文撑持的shape数目。 | |
| rknn_matmul_shape dynamic_shapes[]:矩阵高低文撑持的shape数组。 | |
| rknn_matmul_io_attr io_attrs[]:矩阵乘法输出战输入tensor属性构造体数组。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
const int shape_num = 2;
rknn_matmul_shape shapes[shape_num];
for (int i = 0; i < shape_num; ++i) {
shapes[i].M = i+1;
shapes[i].K = 64;
shapes[i].N = 32;
}
rknn_matmul_io_attr io_attr[shape_num];
memset(io_attr, 0, sizeof(rknn_matmul_io_attr) * shape_num);
int ret = rknn_matmul_create_dynamic_shape(&ctx, &info, shape_num, shapes, io_attr);
if (ret < 0) {
fprintf(stderr, " rknn_matmul_create_dynamic_shape fail! ret=%dn", ret);
return -1;
}
7.2.4.8 rknn_matmul_set_dynamic_shape
rknn_matmul_set_dynamic_shape用于指定矩阵乘法运用的某一个shape。正在创立静态shape的矩阵乘法高低文后,拔取此中一个rknn_matmul_shape构造体做为输出参数,挪用此接心设置运算运用的shape。
| API | rknn_matmul_set_dynamic_shape |
| 功用 | 设置矩阵乘法shape。 |
| 参数 | rknn_matmul_ctx ctx:矩阵乘法高低文。 |
| rknn_matmul_shape* shape:指定矩阵乘法运用的shape。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
ret = rknn_matmul_set_dynamic_shape(ctx, &shapes[0]);
if (ret != 0) {
fprintf(stderr, "rknn_matmul_set_dynamic_shapes fail!n");
return -1;
}
7.2.4.9 rknn_B_normal_layout_to_native_layout
rknn_B_normal_layout_to_native_layout用于将矩阵B的本初外形陈列的数据(KxN)转换为下功能数据陈列体例的数据。
| API | rknn_B_normal_layout_to_native_layout |
| 功用 | 将矩阵B的数据陈列从本初外形转换成下功能外形。 |
| 参数 | void* B_input:本初外形的矩阵B数据指针。 |
| void* B_output:下功能外形的矩阵B数据指针。 | |
| int K:矩阵B的止数。 | |
| int N:矩阵B的列数。 | |
| int subN:即是rknn_matmul_io_attr构造体中的B.dims[2]。 | |
| int subK:即是rknn_matmul_io_attr构造体中的B.dims[3]。 | |
| rknn_matmul_info* info:矩阵乘法的规格疑息构造体指针。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
int32_t subN = io_attr.B.dims[2]; int32_t subK = io_attr.B.dims[3]; rknn_B_normal_layout_to_native_layout(B_Matrix, B->virt_addr, K, N, subN, subK, &info);
7.2.4.10 rknn_matmul_run
该函数用于运转矩阵乘法运算,并将后果保管正在输入矩阵C中。正在挪用该函数前,输出矩阵A战B需求先预备好数据,并经过rknn_matmul_set_io_mem函数设置到输出缓冲区。输入矩阵C需求先经过rknn_matmul_set_io_mem函数设置到输入缓冲区,而输入矩阵的tensor属性则经过rknn_matmul_create函数获得。
| API | rknn_matmul_run |
| 功用 | 运转矩阵乘法运算。 |
| 参数 | rknn_matmul_ctx ctx:矩阵乘法高低文。 |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
int ret = rknn_matmul_run(ctx);
7.2.4.11 rknn_matmul_destroy
该函数用于烧毁矩阵乘法运算高低文,开释相干资本。正在运用完rknn_matmul_create函数创立的矩阵乘法高低文指针后,需求挪用该函数停止烧毁。
| API | rknn_matmul_destroy |
| 功用 | 烧毁矩阵乘法运算高低文。 |
| 参数 | rknn_matmul_ctx ctx:矩阵乘法高低文。 |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
int ret = rknn_matmul_destroy(ctx);
7.2.5 自界说算子数据构造界说
7.2.5.1 rknn_gpu_op_context
rknn_gpu_op_context暗示指定GPU运转的自界说算子的高低文疑息。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| cl_context | void* | OpenCL的cl_context工具,运用时请强迫范例转换成cl_context。 |
| cl_command_queue | void* | OpenCL的cl_command_queue工具,运用时请强迫范例转换成cl_command_queue。 |
| cl_kernel | void* | OpenCL的cl_kernel工具,运用时请强迫范例转换成cl_kernel。 |
7.2.5.2 rknn_custom_op_context
rknn_custom_op_context暗示自界说算子的高低文疑息。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| target | rknn_target_type | 履行自界说算子的后端装备:RKNN_TARGET_TYPE_CPU: CPURKNN_TARGET_TYPE_CPU: GPU |
| internal_ctx | rknn_custom_op_interal_context | 算子外部的公有高低文。 |
| gpu_ctx | rknn_gpu_op_context | 包括自界说算子的OpenCL高低文疑息,当履行后端装备是GPU时,正在回调函数中从该构造体获得OpenCL的cl_context等工具。 |
| priv_data | void* | 留给开辟者治理的数据指针。 |
7.2.5.3 rknn_custom_op_tensor
rknn_custom_op_tensor暗示自界说算子的输出/输入的tensor疑息。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| attr | rknn_tensor_attr | 包括tensor的称号、外形、巨细等疑息。 |
| mem | rknn_tensor_mem | 包括tensor的内存地点、fd、无效数据偏偏移等疑息。 |
7.2.5.4 rknn_custom_op_attr
rknn_custom_op_attr暗示自界说算子的参数或属性疑息。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| name | char[] | 自界说算子的参数名。 |
| dtype | rknn_tensor_type | 每一个元素的数据范例。 |
| n_elems | uint32_t | 元素数目。 |
| data | void* | 参数数据内存段的实拟地点。 |
7.2.5.5 rknn_custom_op
rknn_custom_op暗示自界说算子的注册疑息。构造体的界说以下表所示:
| 成员变量 | 数据范例 | 寄义 |
| version | uint32_t | 自界说算子版本号。 |
| target | rknn_target_type | 自界说算子履行后端范例。 |
| op_type | char[] | 自界说算子范例。 |
| cl_kernel_name | char[] | OpenCL的kernel函数名。 |
| cl_kernel_source | char* | OpenCL的资本称号。当cl_source_size即是0时,暗示文件相对途径;当cl_source_size年夜于0时,暗示kernel函数代码的字符串。 |
| cl_source_size | uint64_t | 当cl_kernel_source是字符串,暗示字符串少度;当cl_kernel_source是文件途径,则设置为0。 |
| cl_build_options | char[] | OpenCL kernel的编译选项。 |
| init |
int (*)(rknn_custom_op_context* op_ctx,rknn_custom_op_tensor* inputs, uint32_t n_inputs, rknn_custom_op_tensor* outputs, uint32_t n_outputs); |
自界说算子初初化回调函数指针。正在注册时,挪用一次。没有需求时能够设置为NULL。 |
| prepare |
int (*)(rknn_custom_op_context* op_ctx, rknn_custom_op_tensor* inputs, uint32_t n_inputs, rknn_custom_op_tensor* outputs, uint32_t n_outputs); |
预处置回调函数指针。正在rknn_run时挪用一次。没有需求时能够设置为NULL。 |
| compute |
int (*)(rknn_custom_op_context* op_ctx, rknn_custom_op_tensor* inputs, uint32_t n_inputs, rknn_custom_op_tensor* outputs, uint32_t n_outputs); |
自界说算子功用的回调函数指针。正在rknn_run时挪用一次。不克不及设置为NULL。 |
| compute_native |
int (*)(rknn_custom_op_context* op_ctx, rknn_custom_op_tensor* inputs, uint32_t n_inputs, rknn_custom_op_tensor* outputs, uint32_t n_outputs); |
下功能计较的回调函数指针,它取compute回调函数区分是输出战输入的tensor的格局存正在差别。久没有撑持,今朝设置为 NULL。 |
| destroy | int (*)(rknn_custom_op_context* op_ctx); | 烧毁资本的回调函数指针。正在rknn_destroy时挪用一次。 |
7.2.6 自界说算子API阐明
7.2.6.1 rknn_register_custom_ops
正在初初化高低文胜利后,该函数用于正在高低文中注册多少个自界说算子的疑息,包罗自界说算子范例、运转后端范例、OpenCL内核疑息和回调函数指针。注册胜利后,正在推理阶段,rknn_run接心会挪用开辟者完成的回调函数。
| API | rknn_register_custom_ops |
| 功用 | 注册多少个自界说算子到高低文中。 |
| 参数 | rknn_context *context:rknn_context指针。函数挪用之前,context必需曾经初初化胜利。 |
| rknn_custom_op* op:自界说算子疑息数组,数组每一个元素是rknn_custom_op构造体工具。 | |
| uint32_t custom_op_num:自界说算子疑息数组少度。 | |
| 前往值 | int 毛病码(睹RKNN前往值毛病码)。 |
示例代码以下:
// CPU operators
rknn_custom_op user_op[2];
memset(user_op, 0, 2 * sizeof(rknn_custom_op));
strncpy(user_op[0].op_type, "cstSoftmax", RKNN_MAX_NAME_LEN - 1);
user_op[0].version = 1;
user_op[0].target = RKNN_TARGET_TYPE_CPU;
user_op[0].init = custom_op_init_callback;
user_op[0].compute = compute_custom_softmax_float32;
user_op[0].destroy = custom_op_destroy_callback;
strncpy(user_op[1].op_type, "ArgMax", RKNN_MAX_NAME_LEN - 1);
user_op[1].version = 1;
user_op[1].target = RKNN_TARGET_TYPE_CPU;
user_op[1].init = custom_op_init_callback;
user_op[1].compute = compute_custom_argmax_float32;
user_op[1].destroy = custom_op_destroy_callback;
ret = rknn_register_custom_ops(ctx, user_op, 2);
if (ret < 0) {
printf("rknn_register_custom_ops fail! ret = %dn", ret);
return -1;
}
7.2.6.2 rknn_custom_op_get_op_attr
该函数用于正在自界说算子的回调函数中获得自界说算子的参数疑息,比方Softmax算子的axis参数。它传进自界说算子参数的字段称号战一个rknn_custom_op_attr构造体指针,挪用该接心后,参数值会存储rknn_custom_op_attr构造体中的data成员中,开辟者依据前往的构造体内dtype成员将该指针强迫转换成C言语中特定命据范例的数组尾地点,再依照元素数目读掏出完好参数值。
| API | rknn_custom_op_get_op_attr |
| 功用 | 获得自界说算子的参数或属性。 |
| 参数 | rknn_custom_op_context* op_ctx:自界说算子高低文指针。 |
| const char* attr_name:自界说算子参数的字段称号。 | |
| rknn_custom_op_attr* op_attr:暗示自界说算子参数值的构造体。 | |
| 前往值 | 无 |
示例代码以下:
rknn_custom_op_attr op_attr;
rknn_custom_op_get_op_attr(op_ctx, "axis", &op_attr);
if (op_attr.n_elems == 1 && op_attr.dtype == RKNN_TENSOR_INT64) {
axis = ((int64_t*)op_attr.data)[0];
}
…
7.2.7.RKNN前往值毛病码
RKNN API函数的前往值毛病码界说以下表所示:
| 毛病码 | 毛病概况 |
| RKNN_SUCC(0) | 履行胜利。 |
| RKNN_ERR_FAIL(-1) | 履行犯错。 |
| RKNN_ERR_TIMEOUT(-2) | 履行超时。 |
| RKNN_ERR_DEVICE_UNAVAILABLE(-3) | NPU装备不成用。 |
| RKNN_ERR_MALLOC_FAIL(-4) | 内存分派掉败。 |
| RKNN_ERR_PARAM_INVALID(-5) | 传进参数毛病。 |
| RKNN_ERR_MODEL_INVALID(-6) | 传进的RKNN模子有效。 |
| RKNN_ERR_CTX_INVALID(-7) | 传进的rknn_context有效。 |
| RKNN_ERR_INPUT_INVALID(-8) | 传进的rknn_input工具有效。 |
| RKNN_ERR_OUTPUT_INVALID(-9) | 传进的rknn_output工具有效。 |
| RKNN_ERR_DEVICE_UNMATCH(-10) | 版本没有婚配。 |
| RKNN_ERR_INCOMPATILE_OPTIMIZATION_LEVEL_VERSION(-12) | RKNN模子设置了劣化品级的选项,可是战以后驱动没有兼容。 |
| RKNN_ERR_TARGET_PLATFORM_UNMATCH(-13) | RKNN模子战以后仄台没有兼容。 |
考核编纂 黄宇



